
当前,国内外新冠肺炎形势依旧严峻,经济、社会等方面受到严重影响。2020年3月以来,清华大学统计学研究中心副教授邓柯、侯琳带领中心博士生刘朝阳、沈翀、王掣,与清华大学地球系统科学系宫鹏教授、徐冰教授团队和国内外相关研究机构合作就新冠肺炎疫情传播规律与防控措施展开深入研究。近日,团队的研究成果“Suppression of future waves of COVID-19: Global pandemic demands joint interventions”在《美国科学院刊》(PNAS)在线发表!

该篇文章基于新冠肺炎可能在冬季卷土重来的大背景,充分考虑气候变化、人口流动等因素,建立数学模型模拟不同干预情景,以寻找针对新冠肺炎再暴发的最优应对措施。研究结果表明实施8周高强度的干预措施来控制局部传染和国际传播是有效且高效的,同时提出分层干预的策略建议,即干预措施首先在“全球干预中心”(Global Intervention Hub,GIH, 即高人口密度、高国际流通的地区)实施,紧接着是其他高风险地区。该文章从全球视角出发,提出按照辐射分层网络、全球联动实施分层干预措施,对降低新冠肺炎再次暴发给公共健康和社会带来的巨大影响有重要意义。
该研究将全球59个高风险地区(其累计病例占全球92.57%)根据人口密度和国际航运情况分为15个“全球干预中心”(GIH)和44个其他高风险地区,采用多人群传染病动力学模型模拟59个地区新冠肺炎的内部传播与时空扩散。其中,模型参数纳入气候变化、家庭结构、人口流动等多因素的影响。模拟干预情景包括:(1)首先在GIH实施,紧接着其他高风险地区同时实施(图1-AE);(2)只在GIH实施(图1-BF); (3)GIH和其他高风险地区同步实施(图1-CG);(4)首先在GIH实施,紧接着其他高风险地区根据当地累计病例翻倍时开始实施(图1-DH)。干预措施实施周期从2-12周逐两周递增,干预措施强度根据降低社区传播风险及国际流动的百分比划分为轻强度(20%)、中强度(50%)和高强度(80%)。不同干预机制模拟的结果对比发现最优的应对措施为首先在所有GIH实施,紧接着是其他高风险地区根据实际情况及时实施8周的高强度干预措施。

文章链接

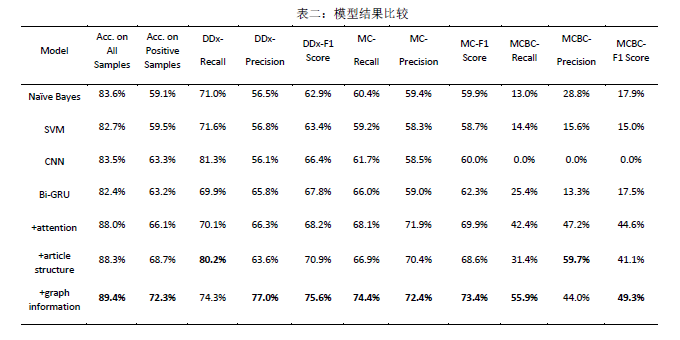



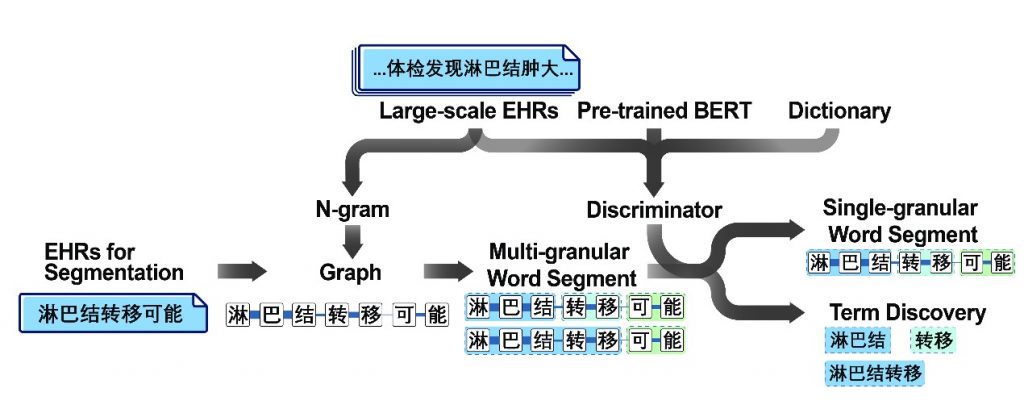
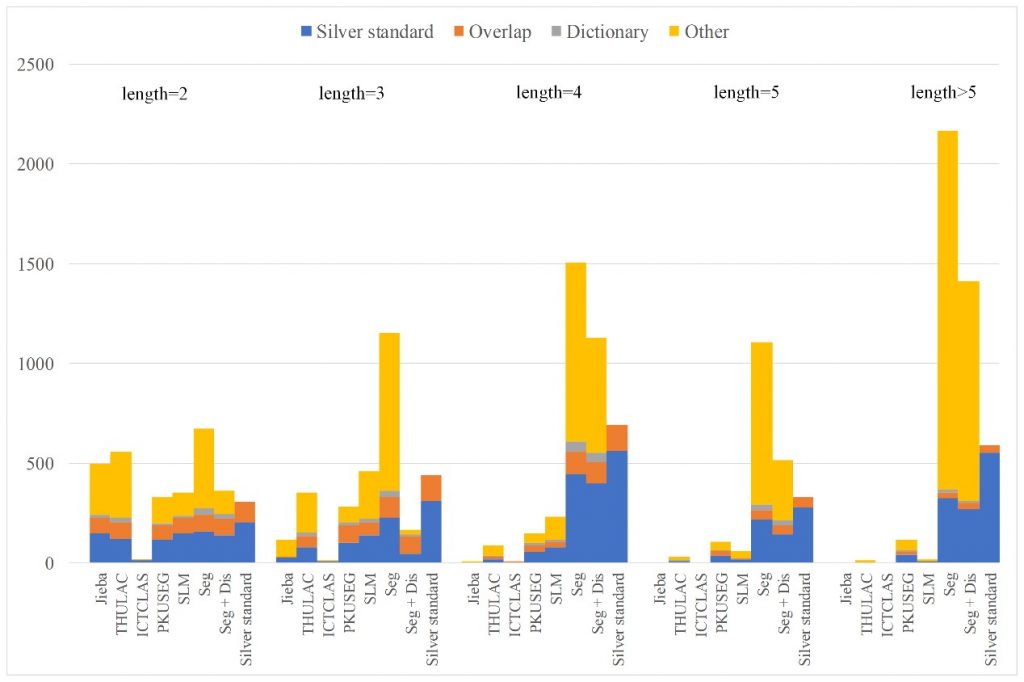




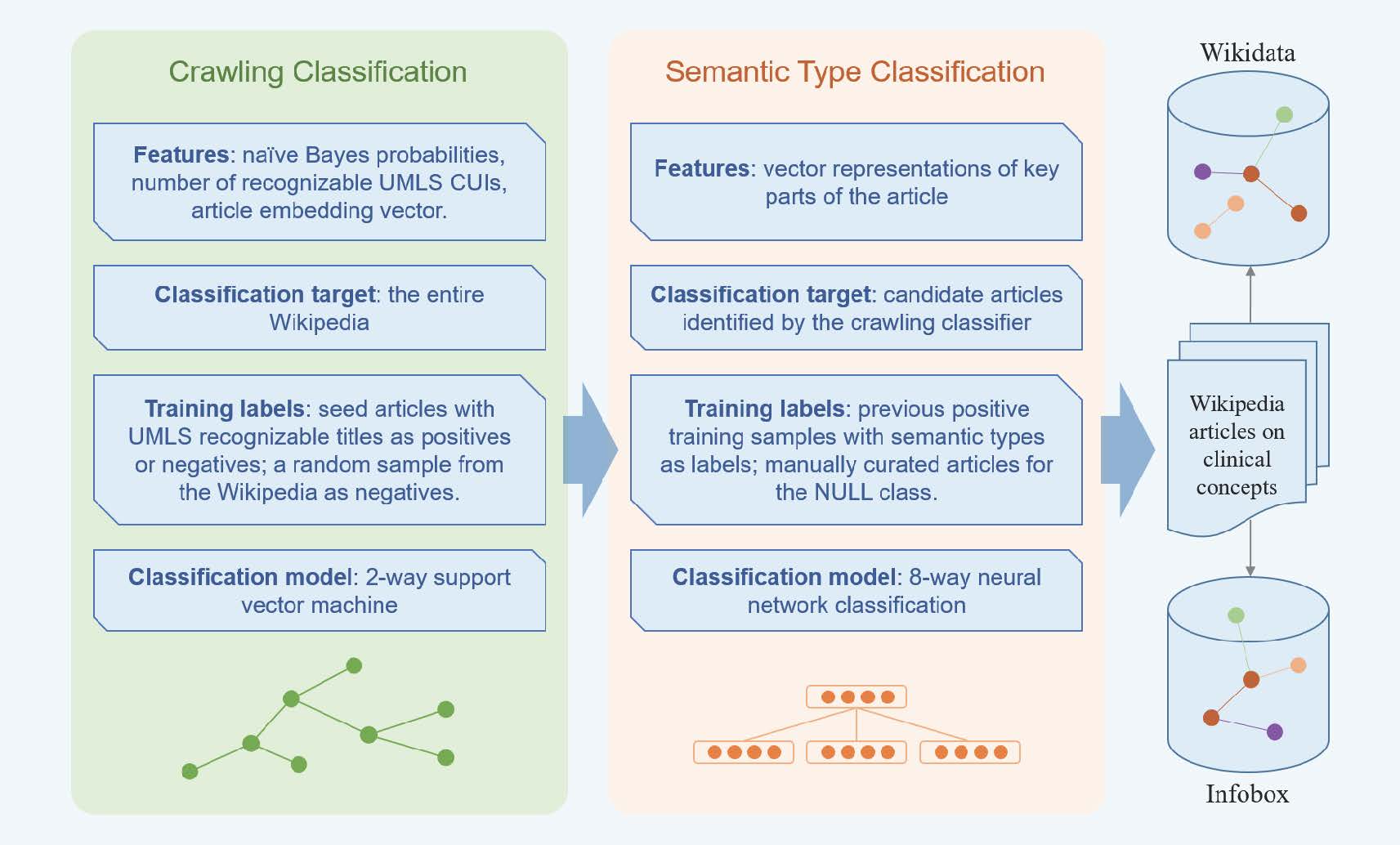


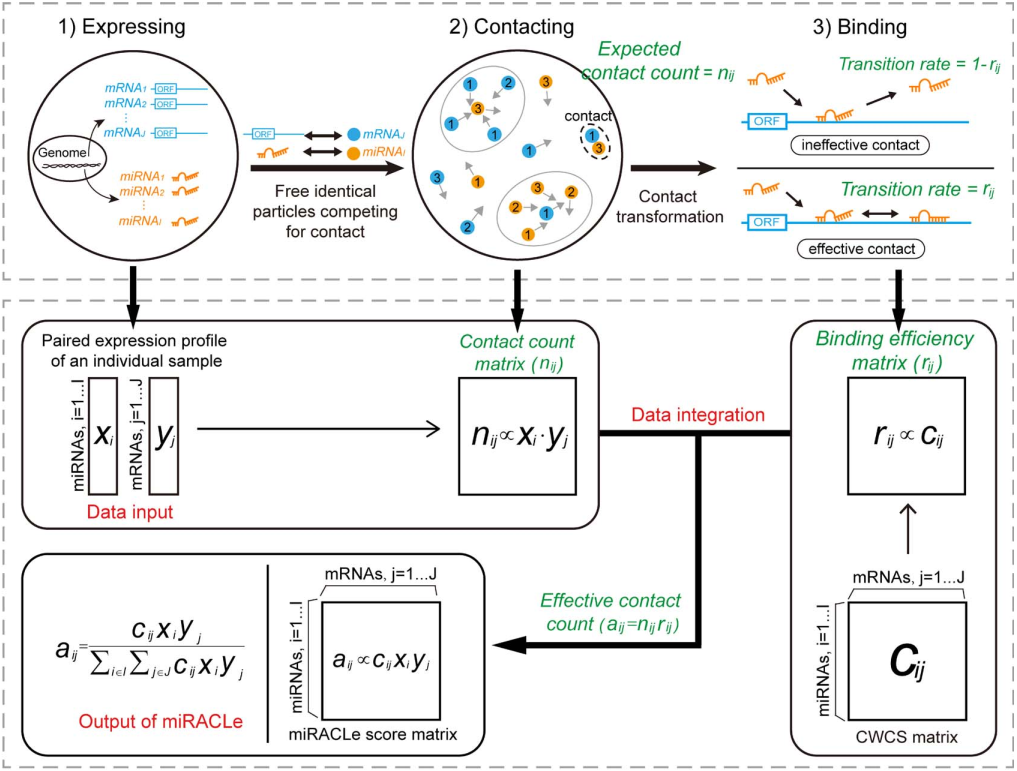


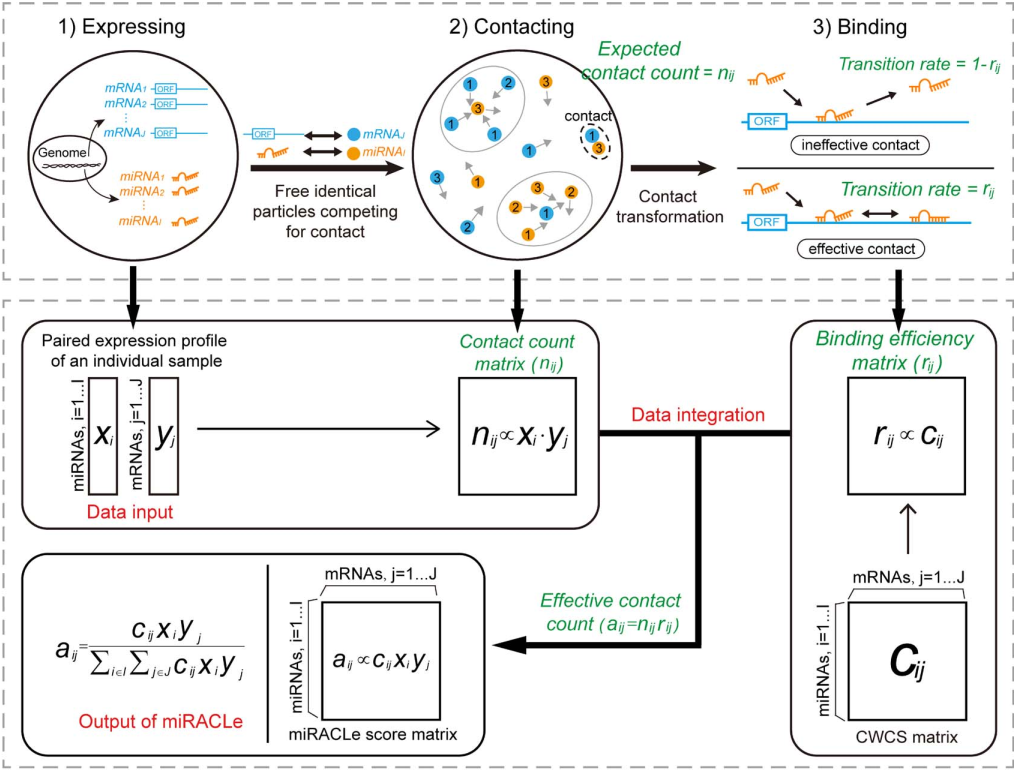

 日前,统计学研究中心17级博士研究生刘朝阳与建筑技术科学系赵彬教授团队合作文章《Outdoor-to-Indoor Transport of Ultrafine Particles: Measurement and Model Development of Infiltration Factor》被环境学领域国际著名期刊Environmental Pollution接收并在线发表。该论文是刘朝阳同学作为统计咨询师,通过咨询中心平台处理建筑技术科学系陈忱同学咨询申请,并同赵彬教授团队建立跨学科交叉合作所产出的学术成果。此前,统计学研究中心16级博士研究生林毓聪也曾通过咨询服务与其他院系科研团队建立合作,并于环境学期刊Environmental Science Water Research & Technology发表文章。
日前,统计学研究中心17级博士研究生刘朝阳与建筑技术科学系赵彬教授团队合作文章《Outdoor-to-Indoor Transport of Ultrafine Particles: Measurement and Model Development of Infiltration Factor》被环境学领域国际著名期刊Environmental Pollution接收并在线发表。该论文是刘朝阳同学作为统计咨询师,通过咨询中心平台处理建筑技术科学系陈忱同学咨询申请,并同赵彬教授团队建立跨学科交叉合作所产出的学术成果。此前,统计学研究中心16级博士研究生林毓聪也曾通过咨询服务与其他院系科研团队建立合作,并于环境学期刊Environmental Science Water Research & Technology发表文章。





