
【学术成果】我中心博士生提出长距离的疾病间关系提取模型

近日,我中心2016级博士研究生林毓聪以第一作者身份撰写的论文 “Long-distance disorder-disorder relation extraction with bootstrapped noisy data” 被医学信息学期刊Journal of Biomedical Informatics (Health Informatics Q1,Computer Science Applications Q1) 接收并在线发表。我中心俞声副教授是论文的通讯作者。
医学知识图谱是医学人工智能应用的基石,知识图谱中先验的关系对于自动诊断等应用的实现都有重要的意义,而现有的一些数据库如Unified Medical Language System虽然囊括了较广泛的医学实体,实体之间的医学关系仍旧比较匮乏。传统的医学关系抽取方法包括人工标注和文本模式匹配,前者费时费力,后者能够提取的关系非常有限,无法适用于现实情况下自然语言多样的表述方式。而在这些医学关系中,疾病与疾病之间较常见的鉴别诊断、导致和被导致关系在医学文本中的表述尤为复杂,常常在一句话中表达了多个疾病的多种关系,抽取尤为困难,使其在现有知识图中(如UMLS和HPO)的覆盖范围不完整。基于这种情况,作者利用深度学习和自然语言处理技术设计了一种新的长距离关系抽取算法,在医学文本的基础上,结合自助法采样及文章章节结构信息抽取了疾病间的鉴别诊断、导致和被导致关系。
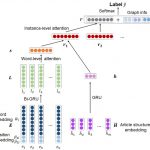
为了解决有标注训练样本缺乏的问题,论文采用远监督的方法构建训练样本,通过半结构化网页获取已知实体关系对,将它们与包含两个实体的所有句子相匹配形成一个训练样本。模型采用Bi-GRU作为句子编码器,结合注意力机制降低噪声样本的影响,将一对实体匹配的所有句子信息融合后再对关系做判断。
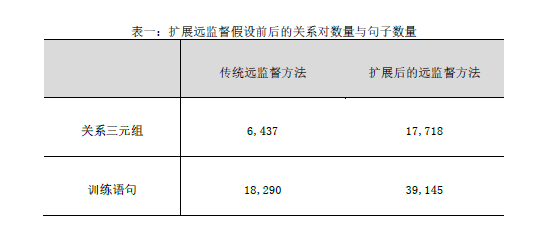
该论文的亮点之一是扩展了远监督的假设,允许其中一个实体出现在文章的标题中。这一假设符合以疾病为标题的网页和医学教科书文本的特点,使得训练句子数量增加了1.17倍,训练样本数增加了0.75倍。
论文的亮点之二是融合了已知关系构成的图信息来更好地区分三类关系。疾病间的鉴别诊断关系通常在文本中的表述都较为模糊,难以直接通过文本判断,而作者发现如果两个疾病跟第三个疾病都有鉴别诊断关系,则他们之间更有可能是鉴别诊断关系而不是导致或被导致关系。基于此发现,作者在模型中融入了已知关系图的信息,有效地帮助模型区分了三类关系。
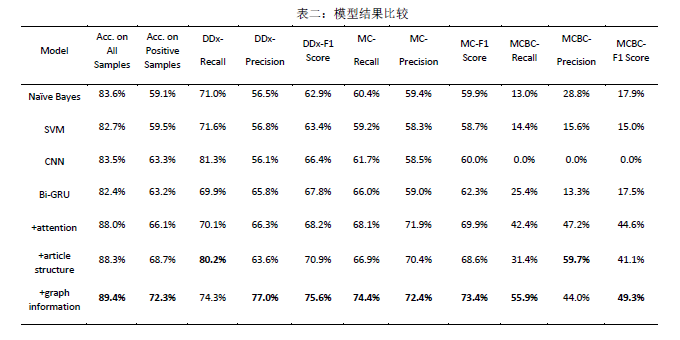
在实验中,作者提出的关系抽取模型(最后一行)准确率接近90%,正样本准确率达到72.3%,比最好的基准模型高出约4.6个百分点。
论文网页链接:
https://www.sciencedirect.com/science/article/pii/S153204642030157X