2021年12月13日,杜克大学洪川助理教授通过线上平台与我中心教员深入交流,并进行线上学术报告,报告的题目是Realizing the Potential of EHR Data for Clinical Research: Overcoming Noisiness, Privacy Constraints and Heterogeneity。

2021年12月13日,杜克大学洪川助理教授通过线上平台与我中心教员深入交流,并进行线上学术报告,报告的题目是Realizing the Potential of EHR Data for Clinical Research: Overcoming Noisiness, Privacy Constraints and Heterogeneity。
中国科学院自动化研究所
职位描述
职位类型:软件/大数据/人工智能
有效日期:2022-01-15
工作地点: 北京 中国科学院自动化研究所
薪资待遇:10k
工作时限:2-6个月
职位描述:
岗位职责:负责配合在研软件系统的方案设计,支持数据分析方案设计与执行;与软件开发人员紧密合作,配合提供大规模人口统计,大规模人群偏好工具研发;负责观察性研究相关论文的撰写与发表;
任职要求: 应用数学或统计学相关领域博士学位或在读博士;或硕士学位,具有3年及以上使用大数据开展某类(例如社交行为)观察性研究的相关经验,有互联网相关的经验者优先考虑;至少掌握一种用于统计建模的统计软件的经验; 有协作大规模人口统计、群众满意度调查工具的经验者优先; 能独立开展工作,自驱力强;
联系方式: 010-82544744 简老师
2021年11月29日,斯坦福大学助理教授通过线上平台与我中心教员深入交流,并进行线上学术报告,报告的题目是Distance-based Summaries and Modeling of Evolutionary Trees。


 11月22-23日,深圳市福田区人民政府、深圳市福田区科技创新局和粤港澳大湾区数字经济研究院(International Digital Economy Academy,简称“IDEA”)联合举办IDEA大会。IDEA创院理事长、美国国家工程院外籍院士、英国皇家工程院外籍院士沈向洋在会上发布了由清华大学统计学研究中心俞声副教授团队与粤港澳大湾区数字经济研究院联合开发的大型开放医学知识图谱(Biomedical Informatics Ontology System,简称“BIOS”)(http://bios.idea.edu.cn)。
11月22-23日,深圳市福田区人民政府、深圳市福田区科技创新局和粤港澳大湾区数字经济研究院(International Digital Economy Academy,简称“IDEA”)联合举办IDEA大会。IDEA创院理事长、美国国家工程院外籍院士、英国皇家工程院外籍院士沈向洋在会上发布了由清华大学统计学研究中心俞声副教授团队与粤港澳大湾区数字经济研究院联合开发的大型开放医学知识图谱(Biomedical Informatics Ontology System,简称“BIOS”)(http://bios.idea.edu.cn)。

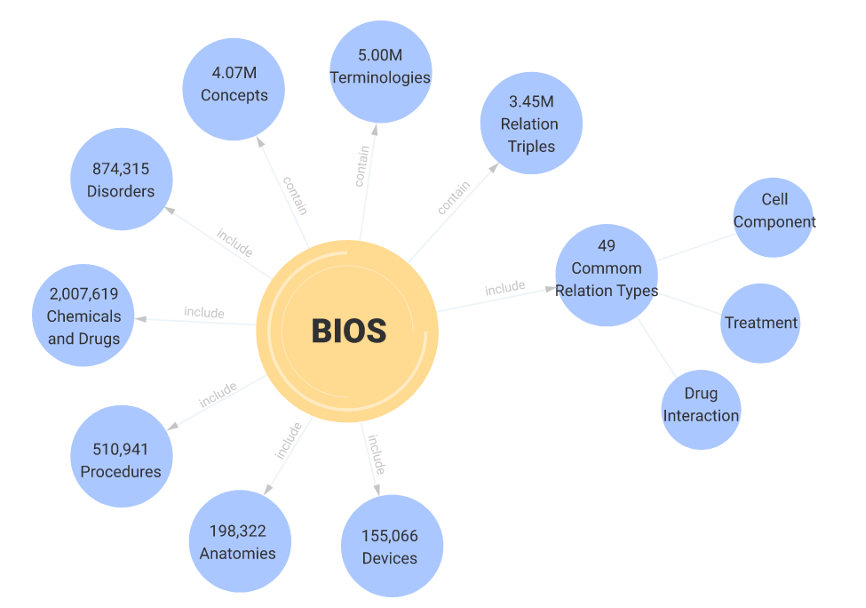
医学知识图谱是一种由生物医学概念名称、概念分类、概念间关系以及相应的ID系统构成的特殊数据库,用于支持医学自然语言处理、人工智能建模以及行业数据交换,是医学大数据与人工智能领域最重要的基础设施之一,对于行业发展具有战略影响。美国国立卫生院国家医学图书馆于1986年开发并发展至今的一体化医学语言系统(Unified Medical Language System,简称“UMLS”)是目前最权威的英文医学知识图谱,为英语国家医学大数据技术与产业的发展做出了卓越贡献。而长久以来,中文领域缺少大型开放医学知识图谱,是我国医疗大数据与人工智能产业发展的主要制约因素之一。
为解决中文领域开放医学知识图谱的缺失,并在国际范围内进一步提升医学知识图谱的建设水平,清华大学统计学研究中心俞声副教授带领团队进行了长达5年的技术攻关,先后开发了基于图分割与深度学习的中文电子病历无监督多粒度分词及术语提取[1]、知识决定的医学术语向量化及正则化[2]、高通量医学关系提取[3,4]、生物医学自动翻译[5]等技术,为数据驱动的大规模图谱自动构建建立了基础,并于2020年11月与IDEA研究院沈向洋院士团队形成合作。在领先算法、强大算力和超大规模语料数据的支持下,仅用短短一年时间,双方团队便从原始底层医学术语开始,建立了全新的具有完整自主知识产权的中英文双语医学知识图谱BIOS,其规模整体接近现有权威知识图谱UMLS,并在内容质量上形成多点超越。未来,清华大学统计学研究中心将与IDEA研究院以及更多国内顶尖医院合作,不断扩大和完善BIOS的内容与质量,不仅要使我国医疗大数据与人工智能产业的薄弱基础得到全面提升,也要辐射国际,带动全球行业共同发展。
BIOS目前已在线发布(bios.idea.edu.cn)。同时,秉承全面提升发展中国医疗大数据与人工智能行业的开放理念,BIOS拟于近期以CC BY-NC-ND协议开放完整数据下载。

1 Yuan Z, Liu Y, Yin Q, et al. Unsupervised multi-granular Chinese word segmentation and term discovery via graph partition. Journal of Biomedical Informatics 2020;110:103542. doi:10.1016/j.jbi.2020.103542
2 Yuan Z, Zhao Z, Yu S. CODER: Knowledge infused cross-lingual medical term embedding for term normalization. arXiv:201102947 [cs] Published Online First: 5 November 2020.http://arxiv.org/abs/2011.02947 (accessed 7 Nov 2020).
3 Lin Y, Li Y, Lu K, et al. Long-distance disorder-disorder relation extraction with bootstrapped noisy data. Journal of Biomedical Informatics 2020;109:103529. doi:10.1016/j.jbi.2020.103529
4 Lin Y, Lu K, Chen Y, et al. High-throughput relation extraction algorithm development associating knowledge articles and electronic health records. arXiv:200903506 [cs, stat] Published Online First: 7 September 2020.http://arxiv.org/abs/2009.03506 (accessed 27 Sep 2020).
5 Luo S, Ying H, Yu S. Sentence Alignment with Parallel Documents Helps Biomedical Machine Translation. arXiv:210408588 [cs] Published Online First: 17 April 2021.http://arxiv.org/abs/2104.08588 (accessed 7 Jul 2021).
2021年11月22日,罗格斯大学龚若玢助理教授通过线上平台与我中心教员深入交流,并进行线上学术报告,报告的题目是Towards Good Statistical Inference from Differentially Private Data。

2021年11月15日,哈佛大学统计系Lucas Janson助理教授通过线上平台与我中心教员深入交流,并进行线上学术报告,报告的题目是Floodgate: inference for model-free variable importance。

近日,我中心邓柯副教授课题组在统计学顶尖期刊Statistica Sinica发表题为“Total- effect Test is Superfluous for Establishing Complementary Mediation ”的研究论文,从数学上严格地证明了当直接效应和间接效应同方向且均统计显著时,利用最小二乘估计(LSE)和F-检验建立中介效应时总效应检验一定是显著的。同时本文还将类似的结果推广到了利用Sobel检验建立中介效应的场景。曾在邓柯课题组攻读博士学位的姜瑛恺博士(清华大学2015级博士生)是该文的第一作者,邓柯副教授作为通讯作者与澳门大学赵心树教授、香港浸会大学朱力行教授和哈佛大学刘军教授共同指导了该文的研究和撰写。

除上述结论之外,研究团队还利用所构造的几何分析方法,对中介效应的各种情形进行了系统分析,从统计推断和几何分析的双重角度对已有文献中关于中介效应检验的结论给予了新的解读。同时,随机模拟实验的结果与理论结果也是完全契合的。以上这些结论与文献中已有的结果相互印证,支持了一个共同的论断:在各种情形下建立中介效应都不需要总效应检验。最后,研究团队通过一份社会学研究数据展示利用中介效应模型进行实际数据分析的方法。
http://www.stat.tsinghua.edu.cn/kdeng/wp-content/uploads/sites/2/2021/11/2019-0150_0326.pdf
2021年11月8日,宾州州立大学马彦源教授通过线上平台与我中心教员深入交流,并进行线上特邀报告,报告的题目是Robust and Efficient Estimation under Nonignorable Missing Response。

2021年11月1日,西南财经大学统计学院谢尚宏助理教授通过线上平台与我中心教员深入交流,并进行线上学术报告,报告的题目是Integrative Network Learning for Multi-modality Biomarker Data。


近日,清华大学教学简报官方发布2020-2021学年度春季学期教评数据
统计中心周在莹老师开设的
《线性回归分析》(理论课100人以上)
《实验设计和分析》(理论课30人以下)
双双获评2020-2021年度春季学期本科生课程课堂教学质量评估前5%
此外,中心两名博士研究生助教获评研究生助教课堂教学质量评估前5%他们分别是
任吉杨《医学统计》课程助教
钟晨《高等数理统计II》课程助教