北京生物医学统计与数据管理研究会(BBA),成立于2015年1月30日,至今为止已经开展过多次生物医学统计与数据管理研究、学术交流、专业培训、理论研讨、对外交流等活动。
BBA 2023年第四季度研讨会将于11月3日下午于位于清华大学东南门的紫清大厦(原紫光国际交流中心)召开。此次会议由北京生物医学统计与数据管理研究会、清华大学和百济神州生物科技有限公司三方联合主办,将围绕“智慧研究与智慧医疗”,由来自国内学界及企业的多位讲者展开汇报和讨论。
讨论内容涉及多个方面,包括:因果推断前沿方法及应用,AI辅助临床决策,数据科学助力临床开发,数智化在临床研究中的应用。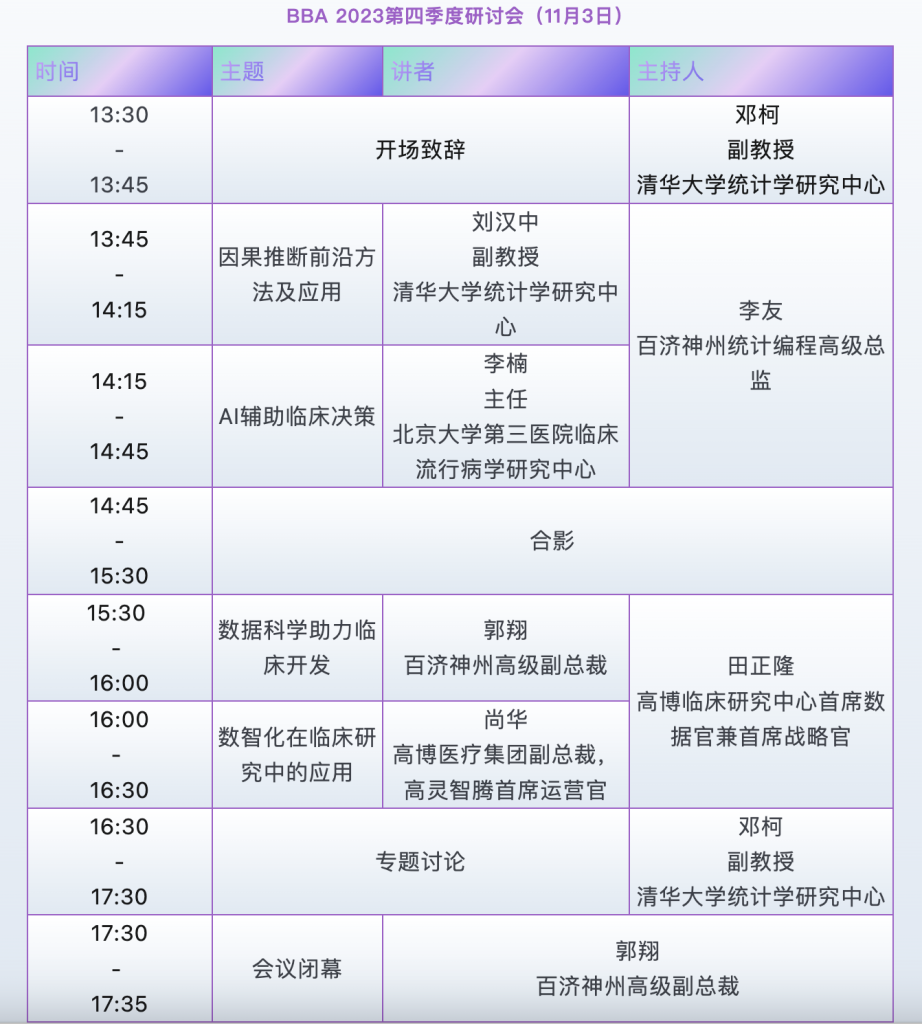
本次会议秉持开放交流,免费参与的原则,线下现场参与名额有限(约100人),欢迎广大业界同仁踊跃报名。
报名方式:扫描下方二维码填写报名信息。
报名截止日期:2023年11月1日

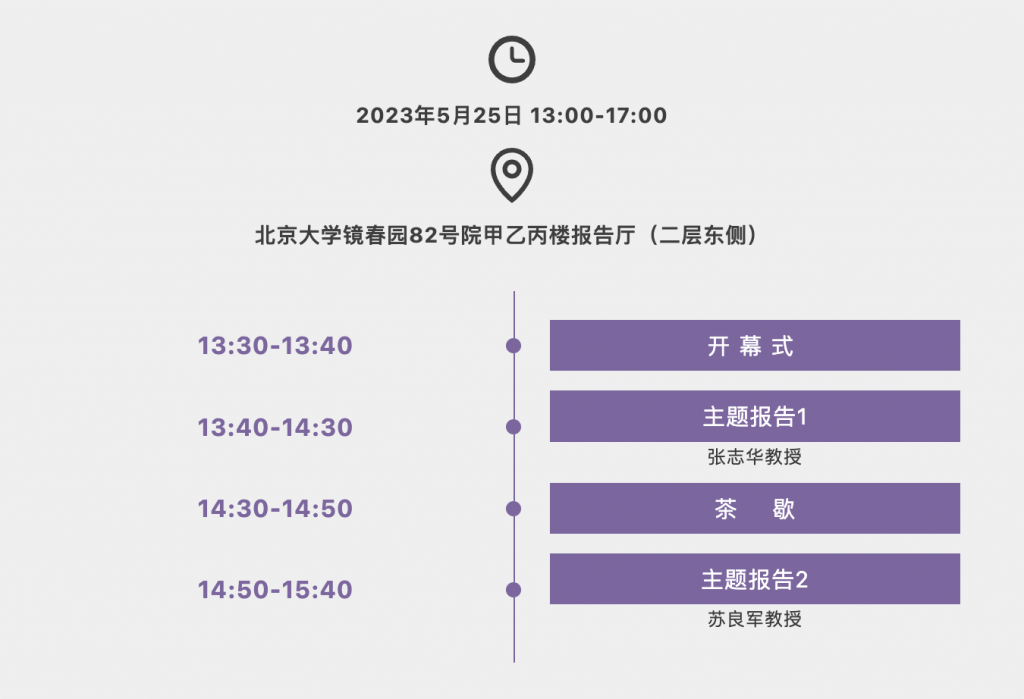
线下会议时间:2023年11月3日13:30-17:35.
线下会议地点:北京市海淀区中关村东路1-10号紫清大厦(原紫光国际交流中心)二层宴会厅
会务联系人:Yushan Hou, houyushan@tsinghua.edu.cn
Rui Chen, ruc_bba@163.com