近日,2022年中国国际服务贸易交易会(以下简称“服贸会”)在北京成功举办,作为本届服贸会亮点之一的“首届卫生健康与工业科技创新服务大会”同期于国家会议中心召开。该会议由工业和信息化部、国家卫生健康委员会和北京市人民政府共同发起主办,聚焦医药创新、成果转化、医工交叉,探讨新形势下医药工业与卫生健康产业融合创新发展,展示前沿技术与创新成果,搭建跨领域、大协作的创新服务平台。


本届卫生健康与工业科技创新服务大会特别设立了“医工成果转化与投融资论坛”专题版块,该版块聚焦“成果转化赋能产业发展”,聚集政府部门、医疗卫生机构、高校及科研院所、企业、投资机构等创新主体,解读政策监管创新,分享成功经验,拓宽投融资渠道,助推医工融合创新科技成果产业化落地。

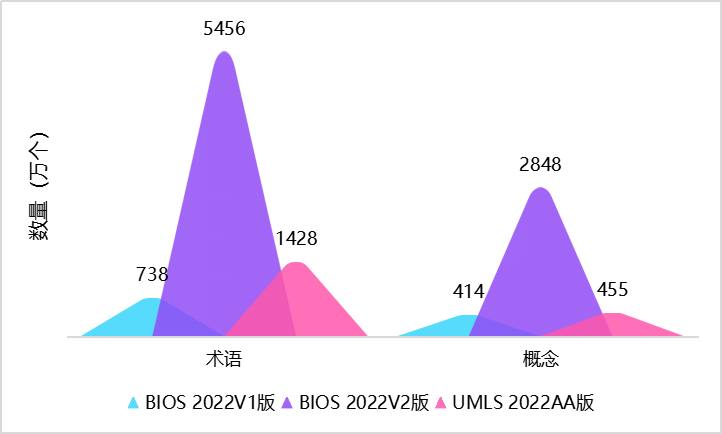
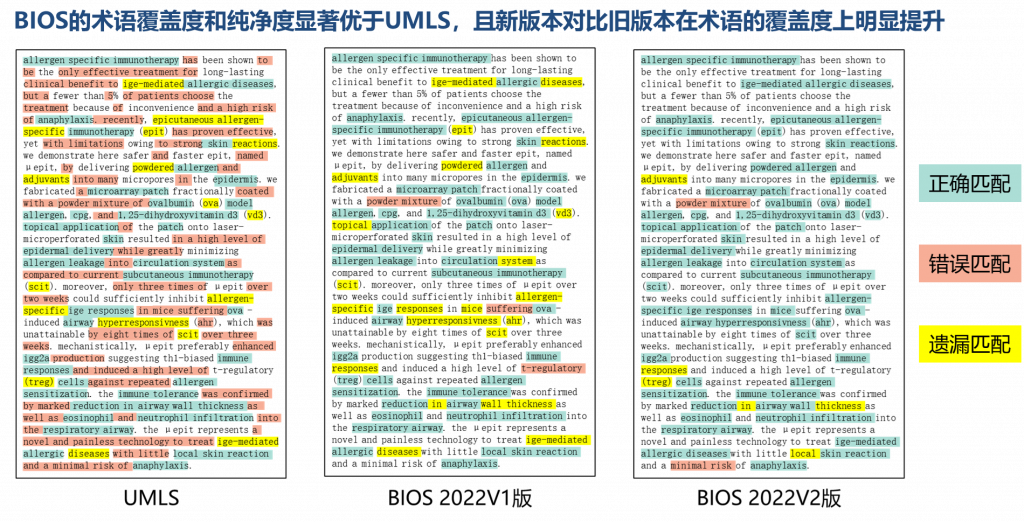
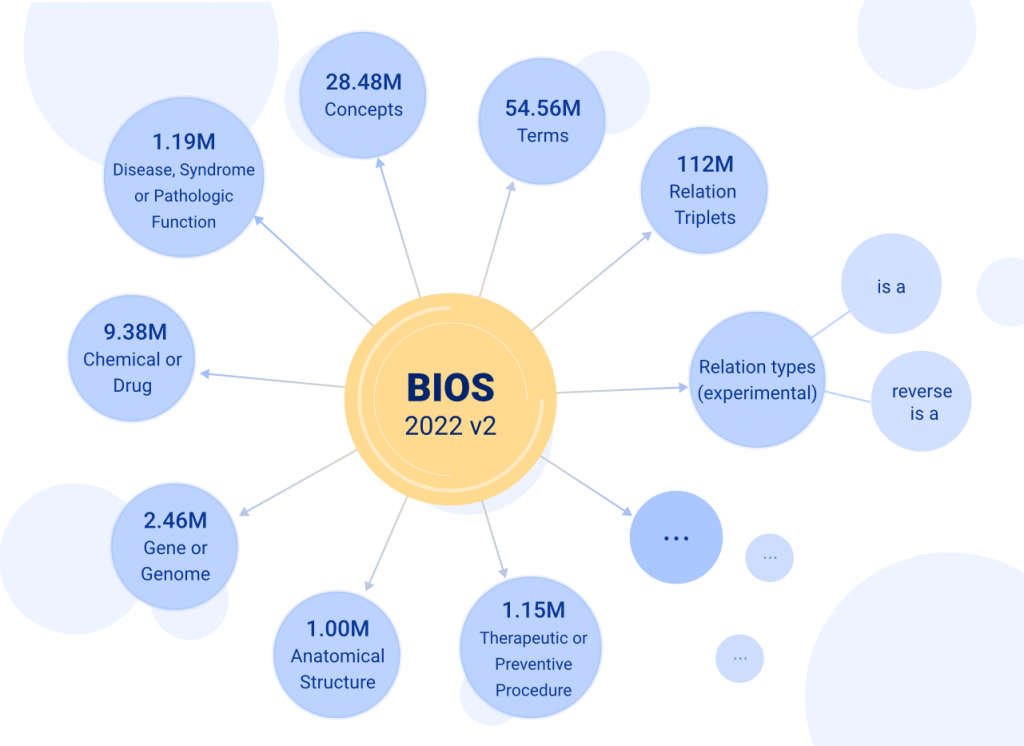
清华大学统计学研究中心俞声副教授课题组和粤港澳大湾区数字经济研究院(IDEA)AI平台技术研究中心联合开发的大型开放生物医学知识图谱——“生物医学信息学本体系统”BIOS(Biomedical Informatics Ontology System)受邀于“医工成果转化与投融资论坛”亮相。BIOS自去年11月发布以来受到广泛关注,今年7月历经重大更新,实现通过借助算法挖掘收录了2800万概念、5500万中英文术语和1.1亿关系三元组,规模上达美国国立卫生院国家医学图书馆开发的“一体化医学语言系统”UMLS(Unified Medical Language System,简称“UMLS”)数倍,同时在术语的纯净度和覆盖度上相比UMLS呈现明显优势,跃升为全球最大开放生物医学知识图谱。

粤港澳大湾区数字经济研究院工程总监谢育涛代表研发团队进行“开放医学知识图谱助力医疗信息平台建设”的主题分享。统计中心俞声副教授作为研发团队代表现场出席论坛。BIOS不但在技术层面达到国际领先水平,更以全公开、全开放的态度助力国内医疗信息领域和AI医疗产业的发展。








 2022年7月,由清华大学统计学研究中心俞声课题组和粤港澳大湾区数字经济研究院(IDEA)AI平台技术研究中心联合开发的大型开放生物医学知识图谱——“生物医学信息学本体系统”BIOS(Biomedical Informatics Ontology System)迎来重大更新,跃升成为世界最大的开放生物医学知识图谱。(
2022年7月,由清华大学统计学研究中心俞声课题组和粤港澳大湾区数字经济研究院(IDEA)AI平台技术研究中心联合开发的大型开放生物医学知识图谱——“生物医学信息学本体系统”BIOS(Biomedical Informatics Ontology System)迎来重大更新,跃升成为世界最大的开放生物医学知识图谱。(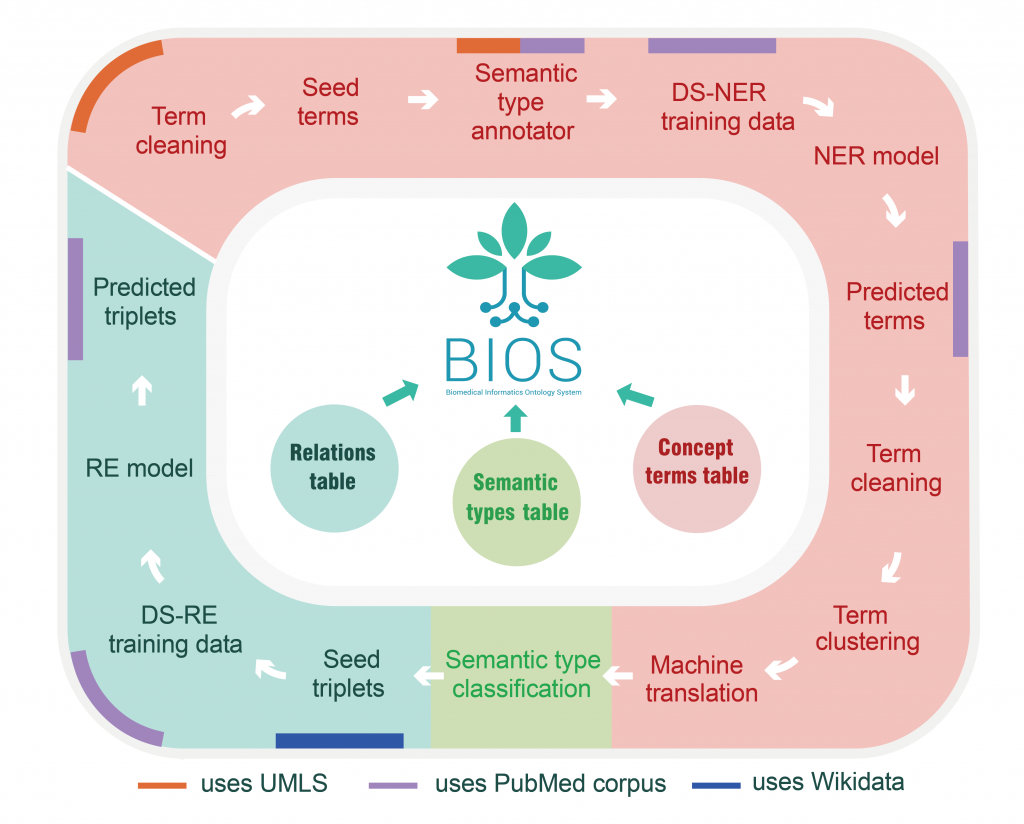
 据悉,清华大学于2006年设立清华大学毕业生启航奖,大力鼓励、支持、引导毕业生将个人成长成才与国家民族发展紧密结合起来,“到党和人民需要的地方发光发热”。作为毕业生就业领域唯一的校级荣誉,重点表彰前往西部、基层、重点行业、艰苦行业就业及创业的优秀毕业生。
据悉,清华大学于2006年设立清华大学毕业生启航奖,大力鼓励、支持、引导毕业生将个人成长成才与国家民族发展紧密结合起来,“到党和人民需要的地方发光发热”。作为毕业生就业领域唯一的校级荣誉,重点表彰前往西部、基层、重点行业、艰苦行业就业及创业的优秀毕业生。 李杰,中共党员,2017年进入清华大学统计学研究中心攻读博士学位,导师为杨立坚教授。博士期间曾获2021年国际统计学会ISI Jan Tinbergen Award First Prize、2020年国际数理统计协会 IMS Hannan Graduate Student Travel Award、2020第四届全国统计学博士研究生学术论坛优秀论文二等奖、2019年第四届北大-清华统计学论坛优秀海报奖、2022年第六届北大-清华统计学论坛优秀毕业生、2021年清华大学综合一等奖学金、2022年清华大学优秀博士学位论文、2018年清华大学工业工程系优秀党员等荣誉,并入选清华大学工业工程系“未来教授培养计划”。他毕业后前往中国人民大学统计学院任师资博士后。
李杰,中共党员,2017年进入清华大学统计学研究中心攻读博士学位,导师为杨立坚教授。博士期间曾获2021年国际统计学会ISI Jan Tinbergen Award First Prize、2020年国际数理统计协会 IMS Hannan Graduate Student Travel Award、2020第四届全国统计学博士研究生学术论坛优秀论文二等奖、2019年第四届北大-清华统计学论坛优秀海报奖、2022年第六届北大-清华统计学论坛优秀毕业生、2021年清华大学综合一等奖学金、2022年清华大学优秀博士学位论文、2018年清华大学工业工程系优秀党员等荣誉,并入选清华大学工业工程系“未来教授培养计划”。他毕业后前往中国人民大学统计学院任师资博士后。