2022年8月31日至9月5日,“中国国际服务贸易交易会”(简称“服贸会”)在京隆重召开。作为“服贸会”配套的高端论坛活动之一,由中华人民共和国海关总署主办的“技术贸易措施助力经济高质量发展和国门生物安全建设高峰论坛”于9月4日在国家会议中心成功举办。论坛围绕“技术贸易措施”主题,从“新形势下技术贸易措施的独特内涵与特征”、“技术贸易措施工作助力经济高质量发展”、“国门生物安全与技术贸易措施对我国治理体系建设的重大影响”三个主题展开研讨。海关总署和北京市相关领导、多国驻华使节和相关领域的专家学者一百余人出席了高峰论坛。

全国人大农业与农村委员会委员、原国家质检总局副局长张沁荣,中国进出口生物安全研究会会长、中纪委原副部级巡视员王炜,中国工程院陈君石院士、陈薇院士、沈建忠院士,中国科学院陈松蹊院士和清华大学统计学研究中心邓柯副教授等专家学者受邀在论坛上做了主题发言。

陈松蹊院士发表题为“运用统计学强化技术贸易措施研究,助力经济高质量发展”的主题演讲。陈院士在发言中指出:随着全球关税水平逐年稳步下降,以技术贸易措施为代表的非关税贸易壁垒已经成为世界各国调整贸易利益的重要手段;运用前沿数据分析方法对技术贸易措施进行深入研究,能够有效保护我国的贸易利益,减少贸易损失,保障贸易安全,助力经济高质量发展,具有重大意义。陈院士还强调:在政务大数据处理中,以先进的统计学理念做好数据治理是基础,将前沿的数据科学技术灵活运用是关键。作为统计学家的代表,陈院士还呼吁并期待统计学在各行各业中会发挥越来越重要的作用,为经济高质量发展做出更多的贡献。

邓柯副教授发表题为“构建技术贸易措施综合指数体系,助力经济高质量发展”的主题演讲。在演讲中,邓柯副教授简要介绍了清华大学统计学团队与海关总署标准与法规中心专家团队在构建“技术贸易措施综合指数体系”方面的研究成果。相关研究综合运用统前沿计学方法和数据科学技术,将海量非结构化、非标准化的技术贸易措施通报转化为结构化、标准化的数据库,进而构建并测算“技术贸易措施开放指数”、“技术贸易措施全球动态图谱”、“全球技术贸易措施综合指数”、“技术贸易措施损害指数”等指数体系,从不同角度和维度分析并呈现全球技术贸易措施当前现状、发展动态和演化趋势,为政府决策提供重要技术支撑。

陈松蹊院士和邓柯副教授的发言引起了与会各界的强烈关注,在服贸会上代表统计学科发出了强音。中央电视台新闻频道报道了相关活动,新闻报道链接如下。
















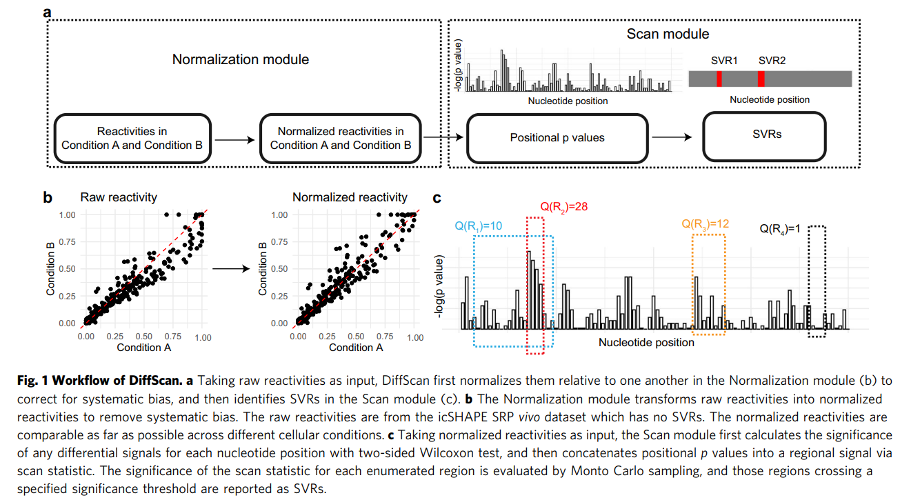

 2022年7月,由清华大学统计学研究中心俞声课题组和粤港澳大湾区数字经济研究院(IDEA)AI平台技术研究中心联合开发的大型开放生物医学知识图谱——“生物医学信息学本体系统”BIOS(Biomedical Informatics Ontology System)迎来重大更新,跃升成为世界最大的开放生物医学知识图谱。(
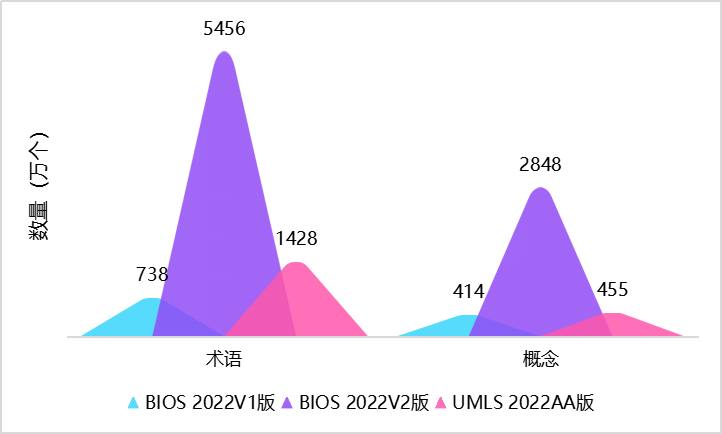
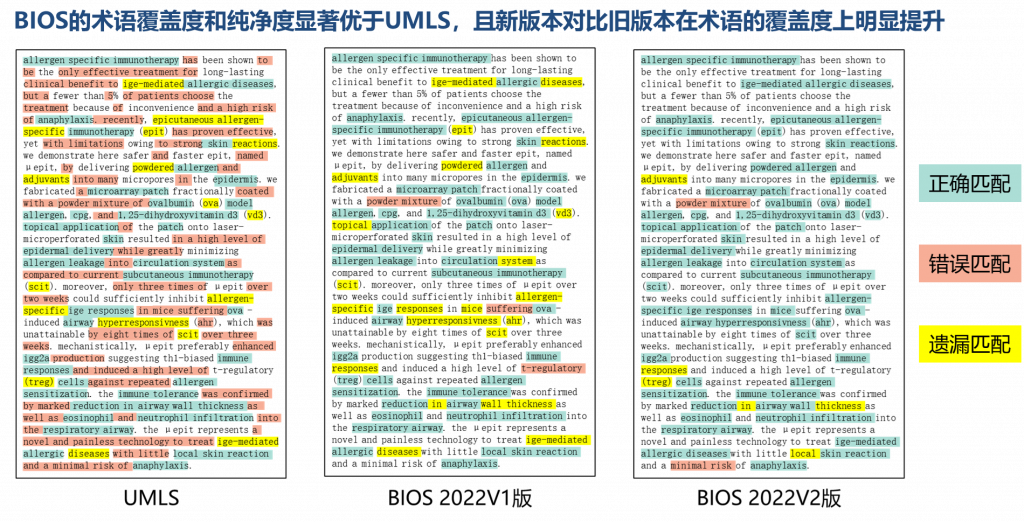
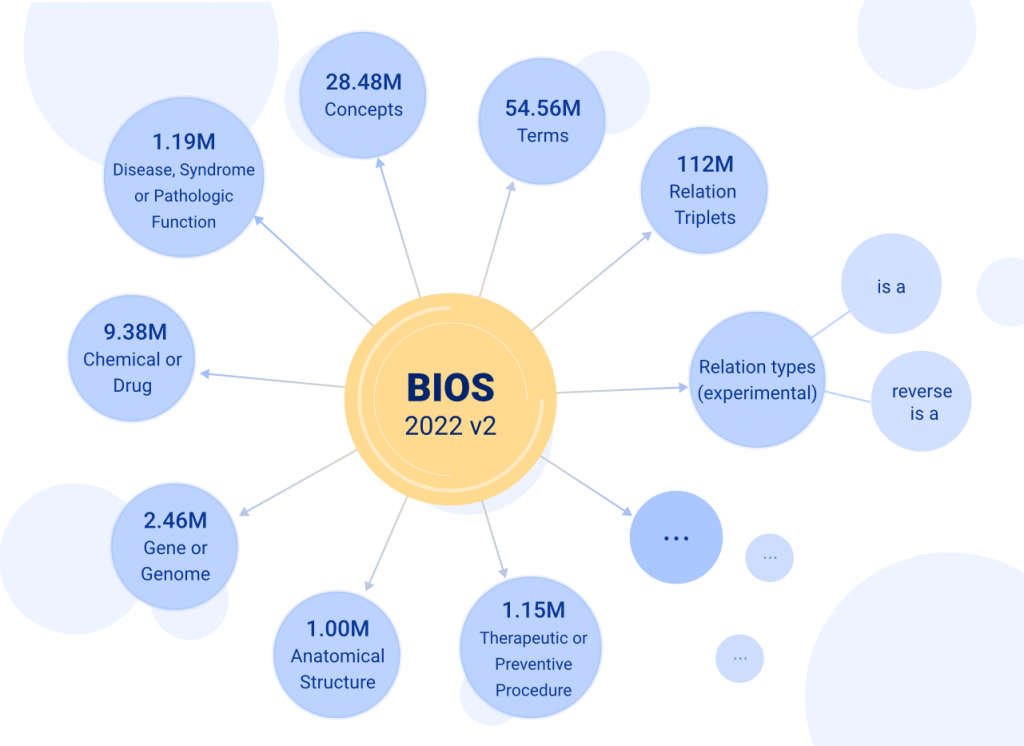
2022年7月,由清华大学统计学研究中心俞声课题组和粤港澳大湾区数字经济研究院(IDEA)AI平台技术研究中心联合开发的大型开放生物医学知识图谱——“生物医学信息学本体系统”BIOS(Biomedical Informatics Ontology System)迎来重大更新,跃升成为世界最大的开放生物医学知识图谱。(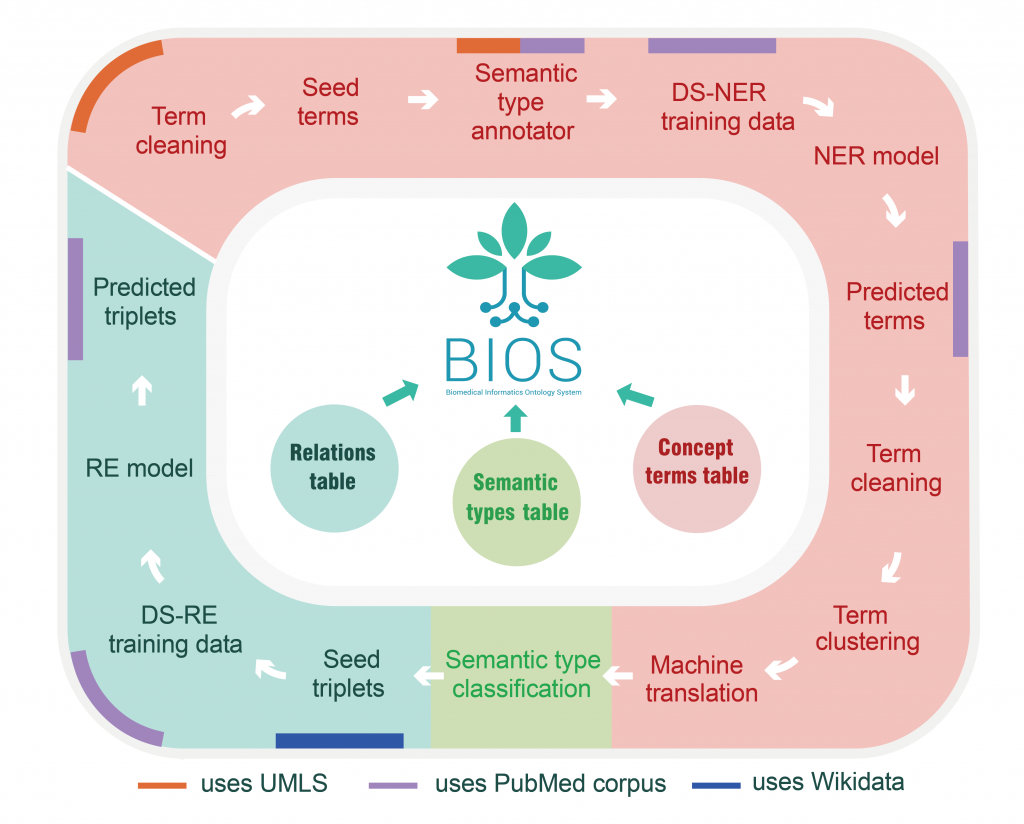
 据悉,清华大学于2006年设立清华大学毕业生启航奖,大力鼓励、支持、引导毕业生将个人成长成才与国家民族发展紧密结合起来,“到党和人民需要的地方发光发热”。作为毕业生就业领域唯一的校级荣誉,重点表彰前往西部、基层、重点行业、艰苦行业就业及创业的优秀毕业生。
据悉,清华大学于2006年设立清华大学毕业生启航奖,大力鼓励、支持、引导毕业生将个人成长成才与国家民族发展紧密结合起来,“到党和人民需要的地方发光发热”。作为毕业生就业领域唯一的校级荣誉,重点表彰前往西部、基层、重点行业、艰苦行业就业及创业的优秀毕业生。 李杰,中共党员,2017年进入清华大学统计学研究中心攻读博士学位,导师为杨立坚教授。博士期间曾获2021年国际统计学会ISI Jan Tinbergen Award First Prize、2020年国际数理统计协会 IMS Hannan Graduate Student Travel Award、2020第四届全国统计学博士研究生学术论坛优秀论文二等奖、2019年第四届北大-清华统计学论坛优秀海报奖、2022年第六届北大-清华统计学论坛优秀毕业生、2021年清华大学综合一等奖学金、2022年清华大学优秀博士学位论文、2018年清华大学工业工程系优秀党员等荣誉,并入选清华大学工业工程系“未来教授培养计划”。他毕业后前往中国人民大学统计学院任师资博士后。
李杰,中共党员,2017年进入清华大学统计学研究中心攻读博士学位,导师为杨立坚教授。博士期间曾获2021年国际统计学会ISI Jan Tinbergen Award First Prize、2020年国际数理统计协会 IMS Hannan Graduate Student Travel Award、2020第四届全国统计学博士研究生学术论坛优秀论文二等奖、2019年第四届北大-清华统计学论坛优秀海报奖、2022年第六届北大-清华统计学论坛优秀毕业生、2021年清华大学综合一等奖学金、2022年清华大学优秀博士学位论文、2018年清华大学工业工程系优秀党员等荣誉,并入选清华大学工业工程系“未来教授培养计划”。他毕业后前往中国人民大学统计学院任师资博士后。