2022年11月15日,杜克大学时丕旭助理教授通过线上平台与我中心教员交流,并进行线上学术报告,报告的题目是Dimension Reduction of Longitudinal Microbiome Data by Tensor Functional SVD。

2022年11月15日,杜克大学时丕旭助理教授通过线上平台与我中心教员交流,并进行线上学术报告,报告的题目是Dimension Reduction of Longitudinal Microbiome Data by Tensor Functional SVD。
2022年11月8日,由海关总署主办的“非关税贸易措施高质量发展论坛”在上海国家会展中心隆重召开,该论坛作为“第五届中国国际进口博览会”配套高峰论坛之一引起广泛关注。论坛以“非关税贸易措施”为主题,围绕“双碳+经济高质量发展、冷链+国门生物安全、数据+指数体系构建、友人+人类命运共同体、企业+产品走向世界”五个议题展开探讨。第十二届全国政协副主席马培华、海关总署副署长孙玉宁、第十三届全国人大农业与农村委员会委员张沁荣、中国进出境生物安全研究会会长王炜、海关总署各司局及地方海关工作人员、国内外的权威学者、专家院士、知名企业家及驻华使节百余人受邀出席论坛。在本次论坛上,海关总署将清华大学统计学研究中心邓柯副教授团队主持研发的“技术贸易措施综合指数体系”作为重点成果进行了发布,得到了各界的强烈关注和广泛好评。央视新闻频道对相关成果进行了报道。

全国人大农业与农村委员会委员、原国家质检总局副局长张沁荣,中国进出口生物安全研究会会长、中纪委原副部级巡视员王炜,中国工程院沈建忠、张改平、范维澄、马军院士,欧洲科学院外籍院士、清华大学孙茂松教授和清华大学统计学研究中心邓柯副教授等专家学者受邀做主旨演讲。

邓柯副教授发表题为“构建技术贸易措施综合指数体系,助力经济高质量发展”的主题演讲。在演讲中,邓柯副教授简要介绍了清华大学统计学团队与海关总署标准与法规中心专家团队在构建“技术贸易措施综合指数体系”方面的研究成果。相关研究综合运用统前沿计学方法和人工智能技术,将海量非结构化、非标准化的技术贸易措施通报转化为结构化、标准化的数据库,进而构建并测算“技术贸易措施开放指数”、“技术贸易措施全球动态图谱”、“全球技术贸易措施综合指数”、“技术贸易措施损害指数”等指数体系,从不同角度和维度分析并呈现全球技术贸易措施当前现状、发展动态和演化趋势,为政府决策提供重要技术支撑。


欧洲科学院院士、中国人工智能学会会士、清华大学计算机科学与技术系孙茂松教授发表题为“运用前沿人工智能助力技术贸易措施综合指数研究”的主题演讲。孙教授表示,面对海关系统海量技术贸易措施文件的数据处理需求,近年来快速发展的自然语言处理技术大有用武之地。将前沿人工智能技术与技术贸易措施研究的具体场景,特别是技术贸易措施综合指数的深入结合,会大幅度提升信息提取和处理的效率,推动技术贸易措施研究迈向智能化,助力相关政府部门和产业界提升贸易能力、减小贸易损失,助力我国经济的高质量发展以及人类命运共同体的建构。在论坛期间,孙茂松教授还接受了央视新闻频道专访,呼吁将人工智能技术与政务大数据研究更加紧密结合。
 央视新闻频道“朝闻天下”报道此次论坛
央视新闻频道“朝闻天下”报道此次论坛
2022年11月7日,西安大略大学Grace Y. Yi教授通过线上平台与我中心教员交流,并进行线上特邀报告,报告的题目是University of Western Ontario How Myths about Noisy Data may Mislead Us。
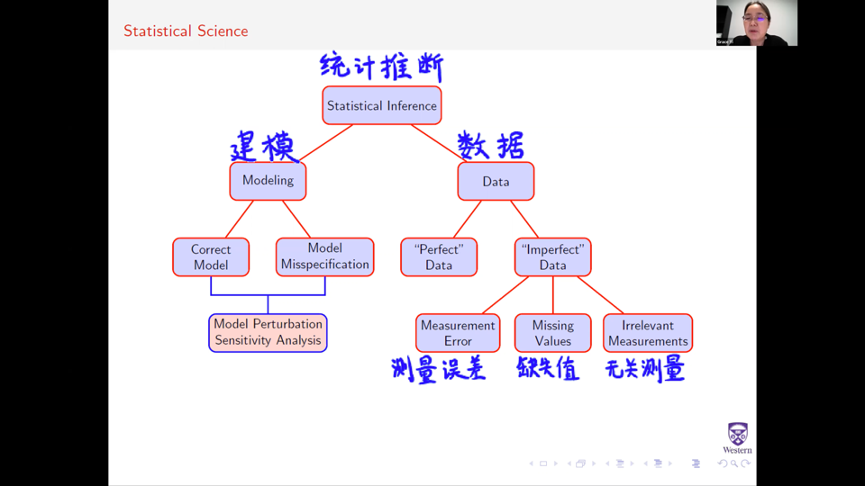



近日,清华大学统计学研究中心邓柯副教授课题组与美国弗吉尼亚大学臧充之教授团队合作,在生物统计学顶级期刊Nature Communications发表了题为Intrinsic bias estimation for improved analysis of bulk and single-cell chromatin accessibility profiles using SELMA的论文。该文章利用单纯形编码改进了高通量测序数据中序列偏倚的量化模型,可以更准确地估计并修正序列偏倚这一酶切内禀属性对开放染色质测序数据的影响。臧充之教授团队的胡圣恩博士为该文的第一作者,邓柯副教授和其课题组李祺博士为共同作者。

全基因组染色质开放区域的分析是研究表观遗传与基因转录调控的主要手段之一。染色质可及性(chromatin accessibility)高通量测序技术(包括基于DNaseI的DNase-seq技术以及基于Tn5转座酶的ATAC-seq技术)可以用来测定全基因组尺度的染色质开放区域图谱,并进而推断细胞核内的转录因子DNA结合位点以及基因表达调控的信息。虽然DNase-seq技术和ATAC-seq技术均为,但DNaseI和Tn5转座酶对于DNA的酶切作用仍然带有一定的序列偏好性,这种偏好性会混杂在高通量测序数据中,给数据分析带来潜在挑战。该现象曾经由哈佛大学刘小乐教授和Myles Brown教授团队在2013年提出。
将ATAC-seq技术与近年来被广泛应用的单细胞测序技术相结合,目前我们可以使用单细胞ATAC-seq(scATAC-seq)方法描绘出单细胞(single cell)或单细胞核(single nucleus)尺度上的染色质开放区域,因此可以极大的拓展数据量,但由于scATAC-seq数据在单细胞层面上极其稀疏,Tn5转座酶的序列偏好性可能造成更为严重的影响。如何对大量单细胞的开放染色质测序数据进行有效纠偏,提升高通量数据的生物学可解释性,仍是计算生物学领域内的一个重要问题。
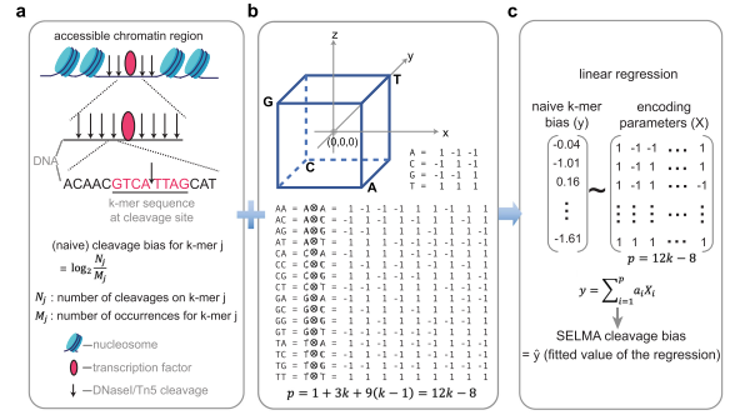
在该文章中,作者提出了名为SELMA (Simplex Encoded Linear Model for Accessible Chromatin)的开放染色质测序数据纠偏算法。在该算法中,作者使用单纯形编码(simplex encoding)模型取代了传统的k-mer模型,从而大大减小了模型参数,参数由缩减为12k-8。在此前提下,该文章可以回收传统DNase-seq/ATAC-seq数据分析中通常被丢弃的线粒体DNA测序片段,用这些数量较小、组成多样性较低的序列片段来准确估计样品数据中的偏倚水平,以此解决了传统方法需要外加DNA酶切样品数据集作为独立参考来进行偏倚水平估计的问题。与此同时,通过分析不同平台产生的单细胞scATAC-seq数据,该方法首次研究了酶切序列内禀偏倚对单细胞开放染色质测序的影响,使用针对单细胞数据的SELMA算法纠偏后,修正的scATAC-seq数据可以获得更加准确的细胞聚类结果。


2022年10月24日,杜伊斯堡-埃森大学 Denis Belomestny教授通过线上平台与我中心教员交流,并进行线上特邀报告,报告的题目是Exploration in Reinforcement Learning via Randomisation。

2022年10月17日,北京大学丁剑教授访问我中心,与中心教员座谈,并做特邀报告,报告的题目是Combinatorial Statistics: a Common Theme and a Few Examples。



2022年10月14日,哥伦比亚大学顾雨琦助理教授通过线上平台与我中心教员交流,并进行线上学术报告,报告的题目是Bayesian Pyramids: Identifiable Multilayer Discrete Latent Structure Models for Discrete Data。