
 2022年7月,由清华大学统计学研究中心俞声课题组和粤港澳大湾区数字经济研究院(IDEA)AI平台技术研究中心联合开发的大型开放生物医学知识图谱——“生物医学信息学本体系统”BIOS(Biomedical Informatics Ontology System)迎来重大更新,跃升成为世界最大的开放生物医学知识图谱。(https://bios.idea.edu.cn)
2022年7月,由清华大学统计学研究中心俞声课题组和粤港澳大湾区数字经济研究院(IDEA)AI平台技术研究中心联合开发的大型开放生物医学知识图谱——“生物医学信息学本体系统”BIOS(Biomedical Informatics Ontology System)迎来重大更新,跃升成为世界最大的开放生物医学知识图谱。(https://bios.idea.edu.cn)
生物医学知识图谱是一种由生物医学概念、术语、关系以及ID系统等要素构成的特殊数据库,是生物医学信息学的重要基础设施。一直以来,由美国开发的“一体化医学语言系统”UMLS(Unified Medical Language System)是生物医学知识图谱的标杆,以455万概念、2095万关系的巨大规模和开放属性,为英文领域生物医药大数据分析、自然语言处理、人工智能开发和数据交换做出了卓越贡献。中文领域由于缺乏可开放获取的大型生物医学知识图谱,导致国内的医学大数据分析缺乏平台基础,科研与技术发展受到严重制约。同时,基于多数据库整合和专家整理的UMLS也日渐老化,其数据质量与发展速度已无法满足大数据与人工智能时代的需要。
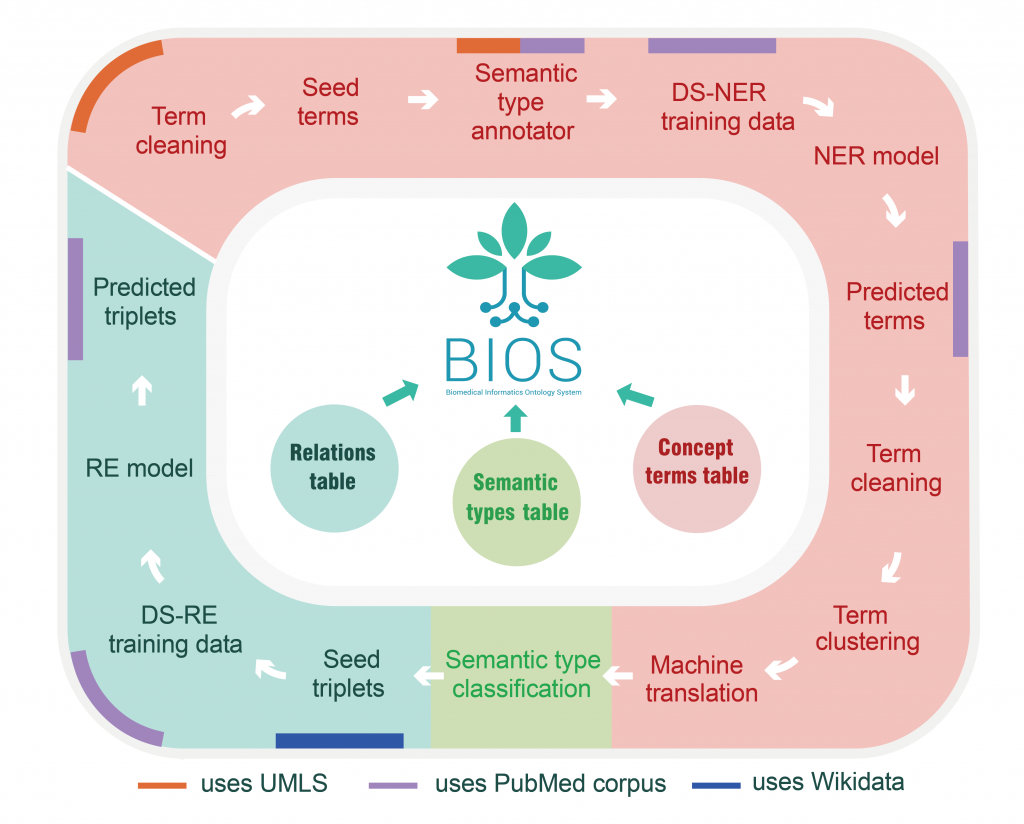
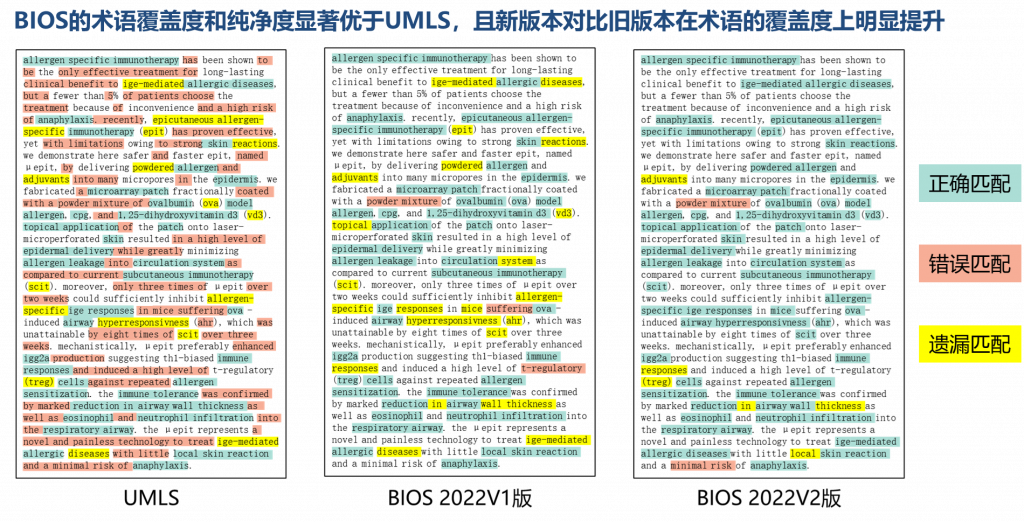
基于算法驱动、开源开放理念,以CC BY-NC-ND 4.0协议发布的BIOS中英文知识图谱自2021年11月发布以来受到了广泛关注。BIOS是首个完全由机器学习算法生成的大型开放生物医学知识图谱,其术语发现、语义分析、概念生成、关系发现、跨语言对齐完全由模型自动实现。在本次更新中,研发团队根据真实数据效果,不断强化算法技术,终于取得了振奋人心的突破性进展,使新版BIOS(2022V2版)一举达到了2848万概念、5456万术语(3348万英文、2108万中文)的巨大体量,术语质量也得到进一步提升。
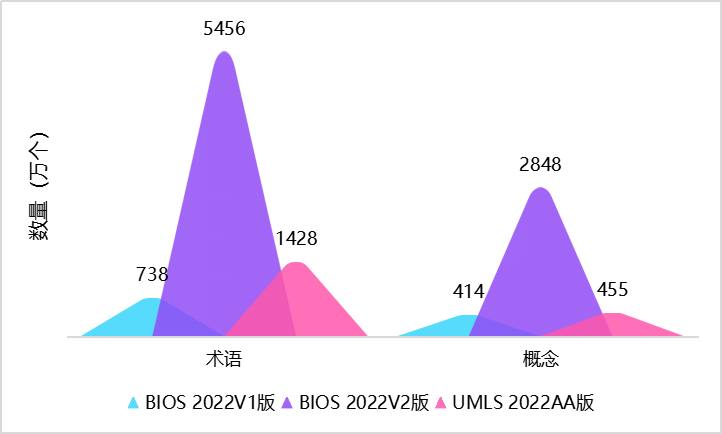
而为了满足如此体量概念的关系挖掘,研究团队创新地提出了由“基于文本的关系提取”到“基于大模型自有知识的关系生成”的模式转变,获得了1.12亿个关系三元组。目前BIOS只包含知识图谱的骨架“上下位关系”的预测,更丰富的关系将在下半年的更新中发布。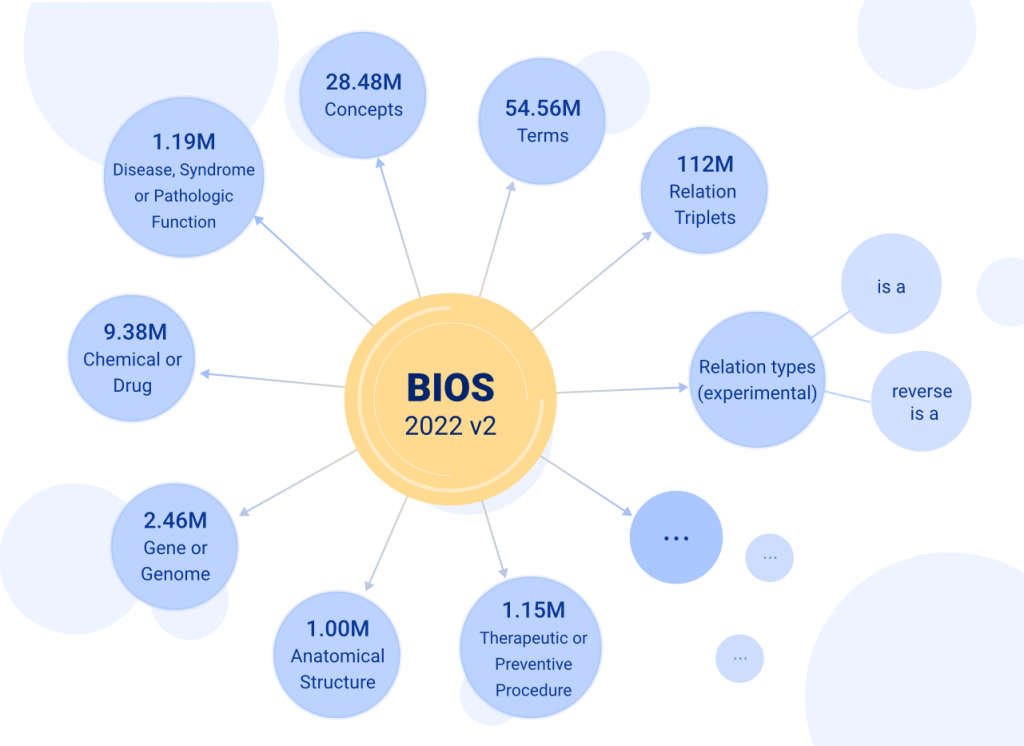
对比开发已有35年的UMLS,BIOS在短短一年半的时间里,使体量达到了UMLS的数倍,不仅扭转了中文领域缺乏大型开放生物医学知识图谱的困难局面,更充分证明了人工智能的巨大潜力。同时,通过BIOS系统的研发,统计学研究中心培养了一批具有数据科学方向理论创新与实战能力的优秀本科生与博士生。未来,统计学研究中心将与IDEA研究院以及更多国内外顶尖医院、科研机构合作,不断扩大和完善BIOS的内容、质量以及相关系统建设,带动并引领生物医学大数据与人工智能行业的发展。

 据悉,清华大学于2006年设立清华大学毕业生启航奖,大力鼓励、支持、引导毕业生将个人成长成才与国家民族发展紧密结合起来,“到党和人民需要的地方发光发热”。作为毕业生就业领域唯一的校级荣誉,重点表彰前往西部、基层、重点行业、艰苦行业就业及创业的优秀毕业生。
据悉,清华大学于2006年设立清华大学毕业生启航奖,大力鼓励、支持、引导毕业生将个人成长成才与国家民族发展紧密结合起来,“到党和人民需要的地方发光发热”。作为毕业生就业领域唯一的校级荣誉,重点表彰前往西部、基层、重点行业、艰苦行业就业及创业的优秀毕业生。 李杰,中共党员,2017年进入清华大学统计学研究中心攻读博士学位,导师为杨立坚教授。博士期间曾获2021年国际统计学会ISI Jan Tinbergen Award First Prize、2020年国际数理统计协会 IMS Hannan Graduate Student Travel Award、2020第四届全国统计学博士研究生学术论坛优秀论文二等奖、2019年第四届北大-清华统计学论坛优秀海报奖、2022年第六届北大-清华统计学论坛优秀毕业生、2021年清华大学综合一等奖学金、2022年清华大学优秀博士学位论文、2018年清华大学工业工程系优秀党员等荣誉,并入选清华大学工业工程系“未来教授培养计划”。他毕业后前往中国人民大学统计学院任师资博士后。
李杰,中共党员,2017年进入清华大学统计学研究中心攻读博士学位,导师为杨立坚教授。博士期间曾获2021年国际统计学会ISI Jan Tinbergen Award First Prize、2020年国际数理统计协会 IMS Hannan Graduate Student Travel Award、2020第四届全国统计学博士研究生学术论坛优秀论文二等奖、2019年第四届北大-清华统计学论坛优秀海报奖、2022年第六届北大-清华统计学论坛优秀毕业生、2021年清华大学综合一等奖学金、2022年清华大学优秀博士学位论文、2018年清华大学工业工程系优秀党员等荣誉,并入选清华大学工业工程系“未来教授培养计划”。他毕业后前往中国人民大学统计学院任师资博士后。