2017年5月12日,耶鲁大学生物统计系系主任,清华大学统计学研究中心学术委员会委员赵宏宇教授访问我中心,并与中心教员及本科生同学交流座谈。


2017年5月12日,耶鲁大学生物统计系系主任,清华大学统计学研究中心学术委员会委员赵宏宇教授访问我中心,并与中心教员及本科生同学交流座谈。
2017年5月10日, 宾夕法尼亚大学生物统计系Li Hongzhe 教授访问我中心并做学术报告 Integrative Analysis for Incorporating the Microbiome to Improve Precision Medicine .





2017年5月8日,乔治华盛顿大学统计系副教授Tatiyana Apanasovich 访问我中心并做学术报告 New Classes of Multivariate Covariance Functions.



本文选自清华大学统计学研究中心开设的统计学辅修课程《数据科学导论》优秀学生成果
小组成员:
张怿良(清华大学数理基科班14级本科生)
张云舒(清华大学数理基科班14级本科生)
金 帆(清华大学自动化系15级本科生)
尹秋阳(清华大学自动化系15级本科生)
指导教师:俞 声
大学排名一直都是社会关注的焦点,尤其是对于学生而言,通过排名了解学校是必不可少的。然而,我们常常会怀疑现存排名的合理性,也关心究竟是哪些因素影响了大学的排名,也好奇过一些简单的指标来判断一所学校的水平。本研究通过爬虫、网络检索等方式获取大学排名相关的数据,并通过相关性分析、机器学习等方法,寻找出大学排名相关的因素和判断顶尖大学水平的方法,并通过大学排名来获取更进一步的信息,如地理位置等。
究竟什么样的大学才是好的大学?
不得不承认的是,给大学排名本身是一个困难的、主观的、有争议的课题。迄今为止,全世界各个地区有上百套不同的大学评价体系。他们运用不同的特征,采取不同的方法,针对不同地区的大学,给出了他们所认为的全世界大学排行榜供世人参考。许多得出的排名和结论往往还是相冲突的。
关于大学排名,我们主要关注以下几点:
1.1.1 大学间的相对位次
是指某两所大学间的孰优孰劣。众所周知,全世界不同区域都有顶尖大学互相掐架。从清华与北大,哈佛大学和MIT再到加州伯克利分校和斯坦福大学,很多学校因毗邻的地理位置和相近的学术成就,都在不断竞争希望能够在排名上高于对方。
1.1.2 世界优秀大学分布
是指世界优秀大学的地理分布。优秀大学有集聚性,我们会关心世界上优秀大学都在哪里,他们有哪些相似性。
1.1.3 现有评价体系特征
基于现有评价体系琳琅满目,不免让人对评级体系内部流程产生兴趣。我们会关心各种评价体系的不同侧重点,也会关心评价体系内部特征相关性和合理性。我们想知道的是,一个大学的优秀程度究竟和哪些特征的相关性最大?
1.1.4 获取排名的简单途径
由于大多数排名中的指标和特征很难被普通人获取(例如一些论文发表数、校友评价等等),普通人只能通过看排名得知大学好坏,却无法自己通过简单分析得到。我们所关注的是,存不存在一种简单、易获取的评价特征。让普通人也可以很快定性得出大学排名和大学好坏。
我们期望通过自己一学期《数据科学导论》的学习,体验整个从数据收集、数据清洗到分析、可视化的数据处理过程,从而回答以上我们所关心的有关大学排名的问题。
Kaggle 是一个数据分析的竞赛平台, Kaggle上的“世界大学排名”数据集(https://www.kaggle.com/mylesoneill/world-university-rankings )中包含了三种大学排名体系的公开数据,其中一种是Times Higher Education World University Ranking(THE)。THE的数据集情况如下:

2.2.1 大学之间的“相关条目数”(弃用)
某个大学的词条数可以作为一个很好的特征去分析大学。在单个大学搜索的基础上,我们产生了分析“相关条目数”的想法。我们的想法是基于这样的假设:如果大学A和大学B是相似的,则他们共同的搜索结果比较多,原因在于他们往往共同出现。

我们发现,我们的这种假设不能和上述数据符合。因此,我们放弃了这种检验各学校两两之间相关性的做法。
2.2.2 院校论文总数的爬取(Bing学术)
在2.2.1节爬取搜索结果条目数时,我们发现不同搜索引擎的条目数相差较大,在通用搜索引擎中,排名相近的学校的条目数也相差很大。为了解决这个问题,我们认为相比于通用网页搜索,学术领域的垂直搜索得到的页面数更加准确;同时,论文总数也是我们考查的一个重要指标。
2.2.3 结果对比:论文总数 v.s. Bing学术条目数
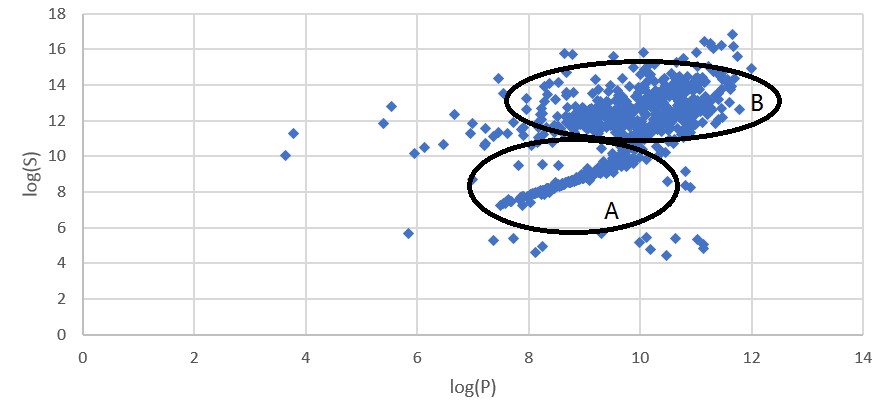 Fig. 论文总数和Bing学术条目数的关系
Fig. 论文总数和Bing学术条目数的关系
图线呈现出一个逗号的形状,这是一个有趣的发现。
依照逗号形图线,学校被大致分为了两类。对此我们的解释是:对于A类学校,它们的论文在发表后很少被再次引用,因而条目数和论文数非常接近。而对于B类学校,它们的论文被多次引用,因而同一篇论文实际上关联着多个条目。
2.2.4 最能反映学校排名的指标是论文总数

(图:P、S、W和学校排名R之间的关系)
从这个图中看出,P、S、W三个指标均和学校排名呈现(近似线性的)负相关。我们认为使用波动最小的论文总数来衡量一个学校的排名更加合理。这与后文更进一步的分析结果相符。
同时,我们发现,通用搜索的结果参考价值不大。可以从下图看出,Bing普通搜索的条目数W与其他两个指标之间相关性很弱(线性回归的R^2<0.2),且变化幅度不大,因而W指标并没有明显的参考价值。
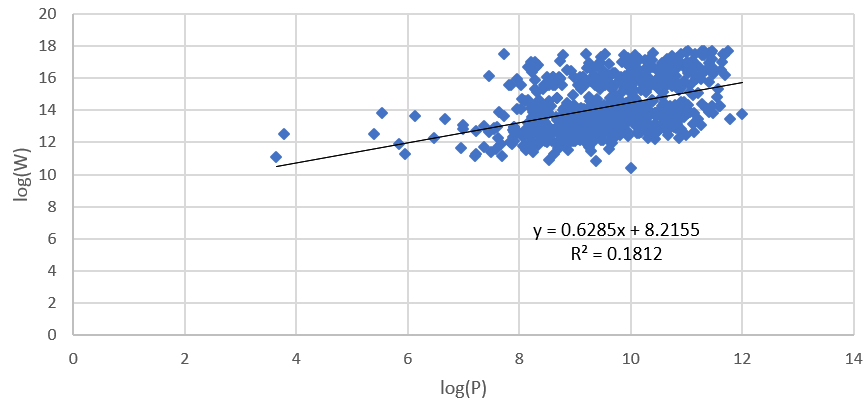
(图:W和P之间的关系)
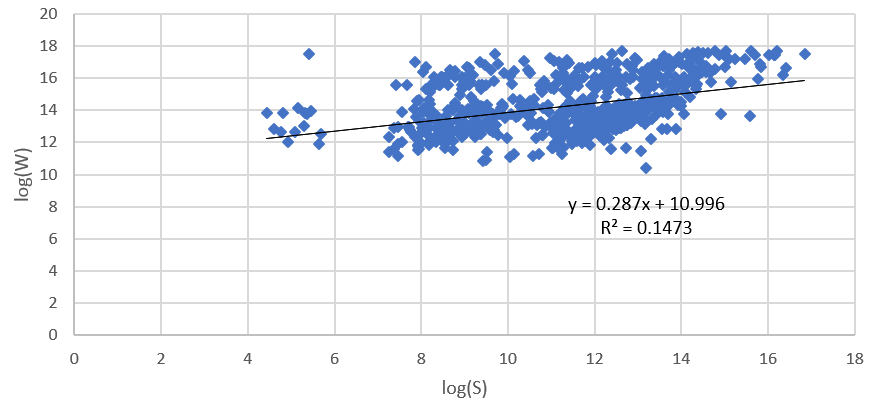
(图: W和S之间的关系)
2.2.5 小结
本节中,我们将抓取到的3个指标(W、P、S)和排名R进行对比,得出了以下几个结论:
2.2.6 网页数据爬取遇到的问题和解决方法
2.2.6.1 字符编码问题(Bing学术)
我们发现,Bing学术并不会像普通搜索那样具备模糊搜索的功能,学校名称必须准确无误地输入才能得到学校的知识卡片。我们在爬取前对800个学校名称做了以下处理:
2.2.6.2 条目数与大学所在国的语言有关
改用学术搜索的结果,而非通用搜索引擎。

2.3.1 基本的数据清洗
在R软件中导入数据Kaggle中THE数据集,发现有如下问题:
2.3.2 学校总分的补全
学校的总分(total_score)是直接反映排名的指标,也是我们最关心的指标。但是,数据集中的总分只给出了前200名的具体数字,后面的学校只有大致排名范围,这显然不利于我们后面的数值上的分析。
一个直接的想法是对前200的总分作其他指标的线性回归,再将得到的线性公式去计算后面的总分。但通过登陆THE官网查阅资料,我们找到了计算总分的公式:

![]()
2.3.3 爬虫数据的整合
通过上述过程,我们完成了kaggle数据集的清洗。现在,我们需要将爬虫爬到的数据整合进来,以方便我们进行后续的分析。使用dplyr包中的left_join函数,我们将爬虫获得数据整合到数据表中。
在对kaggle上的数据集进行了数据清洗后,再综合爬虫得到的数据,我们调用corrgram函数,得到了如下非常便于观看的相关图:
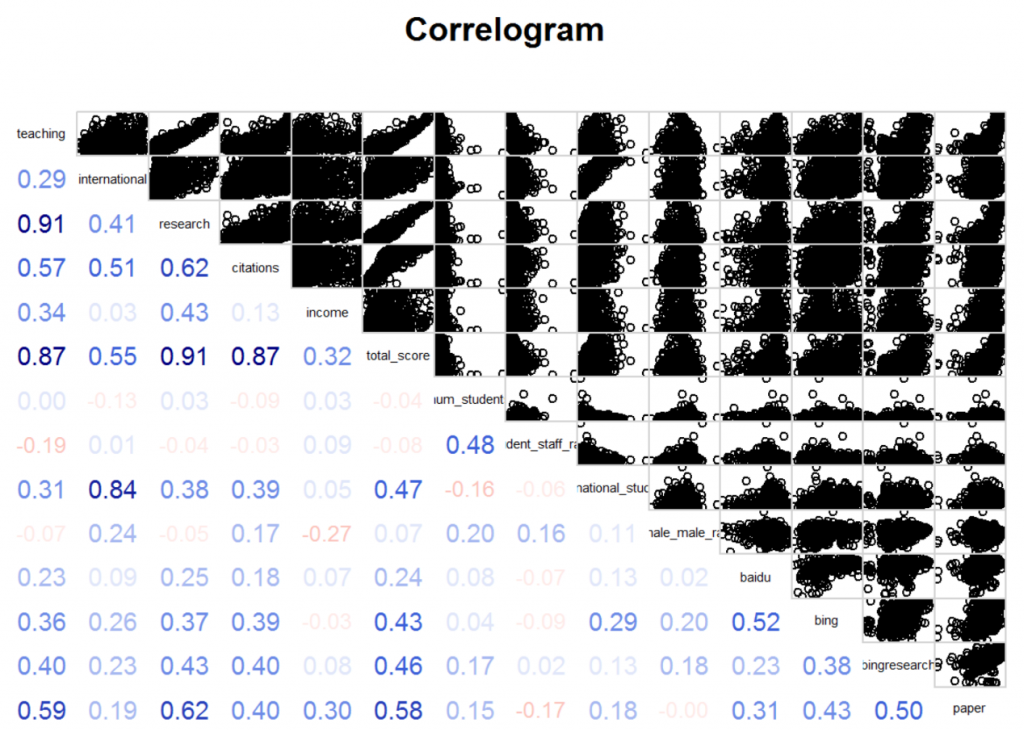
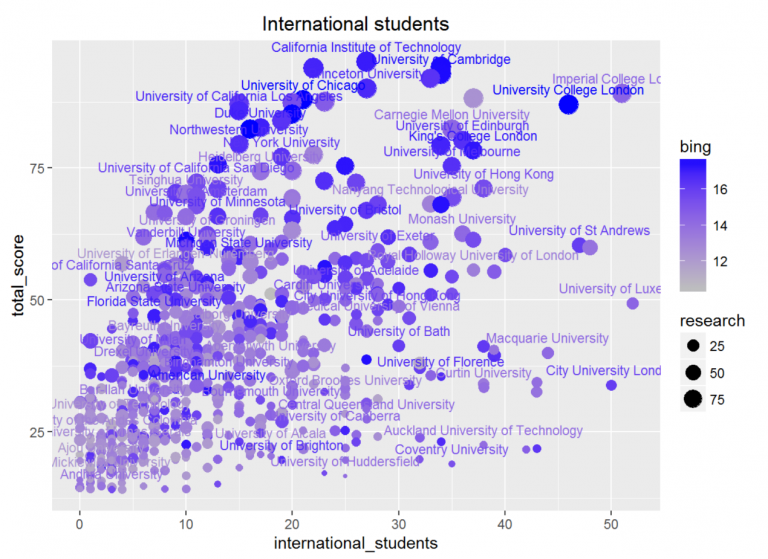
其中,对角线上是各个指标,从左上到右下分别是教学得分、国际化得分、研究得分、引用得分、收入得分、总分、学生数、生师比、国际生比例、女男比、百度搜索页面数、必应搜索页面数、必应学术搜索页面数、论文总数。
左下的数字是所对应横纵坐标两个指标的相关系数(如教学得分和研究得分的相关系数就是0.91),其中,蓝色表示正相关,红色表示负相关,颜色越深,相关系数越大,我们越需要关注,颜色越浅,相关系数越小,因此,我们只需要特别注意非常显眼的数字。
右上的图以其对应的两个指标为横纵坐标绘制出的散点图。可以发现,这其中的许多图都有很多的离群值(outlier),使得散点图无法很好地体现数据之间的相关性关系。使用Mahalanobis距离可以去掉大部分的离群值,再通过对单个变量的特别处理,我们得到如下的相关图。
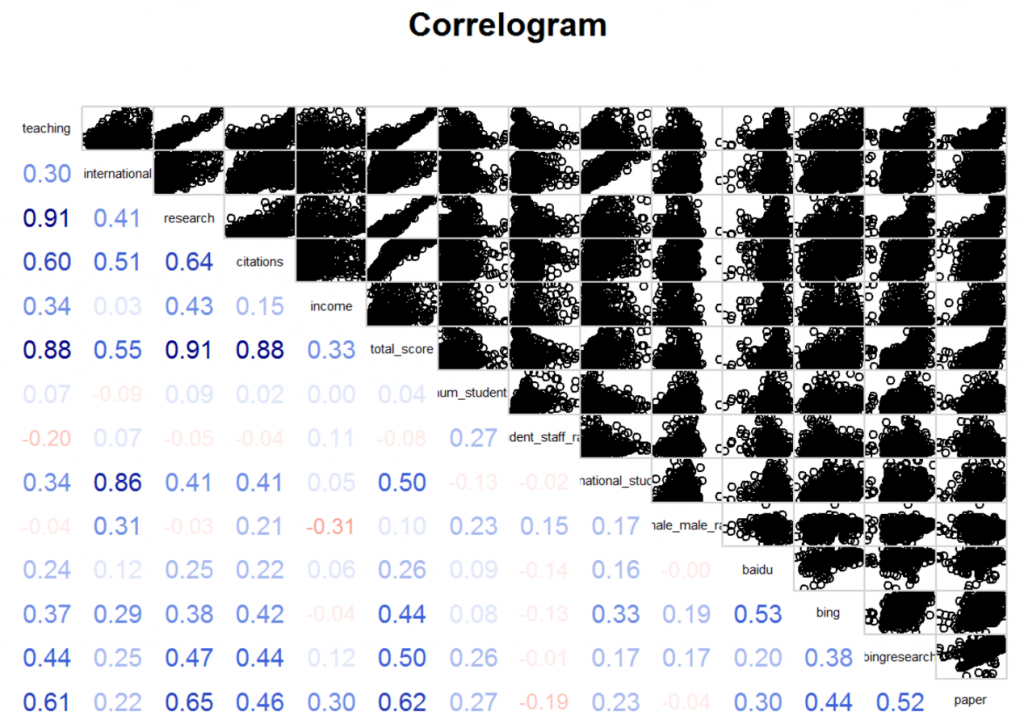
3.2.1显然的相关性
总分与教学得分、国际化得分、研究得分、引用得分、收入得分有非常强的相关性(原因在于总分是由这五项得分线性组合得到的)
教学得分和研究得分高达0.91(有可能是因为评分有比较大的overlap)
国际化得分与国际生比例的相关系数达到了0.86
研究得分与引用的相关系数达到了0.64
学生数量与生师比的相关系数为0.27
几个搜索引擎之间的数据存在着比较高的相关性
3.2.2 隐蔽的相关性
3.2.2.1 学生数量
可以发现,学生数量这一指标与其他数据的相关性都不算高,尤其是与前六项体现学校水平的指标几乎毫不相关,这是一个非常有意思的结果。有些人认为学生太多的话教学质量显然不会太高,比如一些为了提高国民平均教育水平的基础教育大学,重点并不会放在研究上。但另一方面,如果一个学校学生过少,这个学校的水平也不可能太高,因为它无法吸引优秀的学生报考。所以,数据标明这两种因素的平衡使得相关性几乎接近于零。
下图是学生数量关于总分、教学水平、研究水平的散点图,可以发现,学生数量很高的大学水平都不高,这也印证了上面的第一条分析。但学生数量较少的大学的水平几乎遍历了整个区间,我们很难对此做出学校水平的判断。
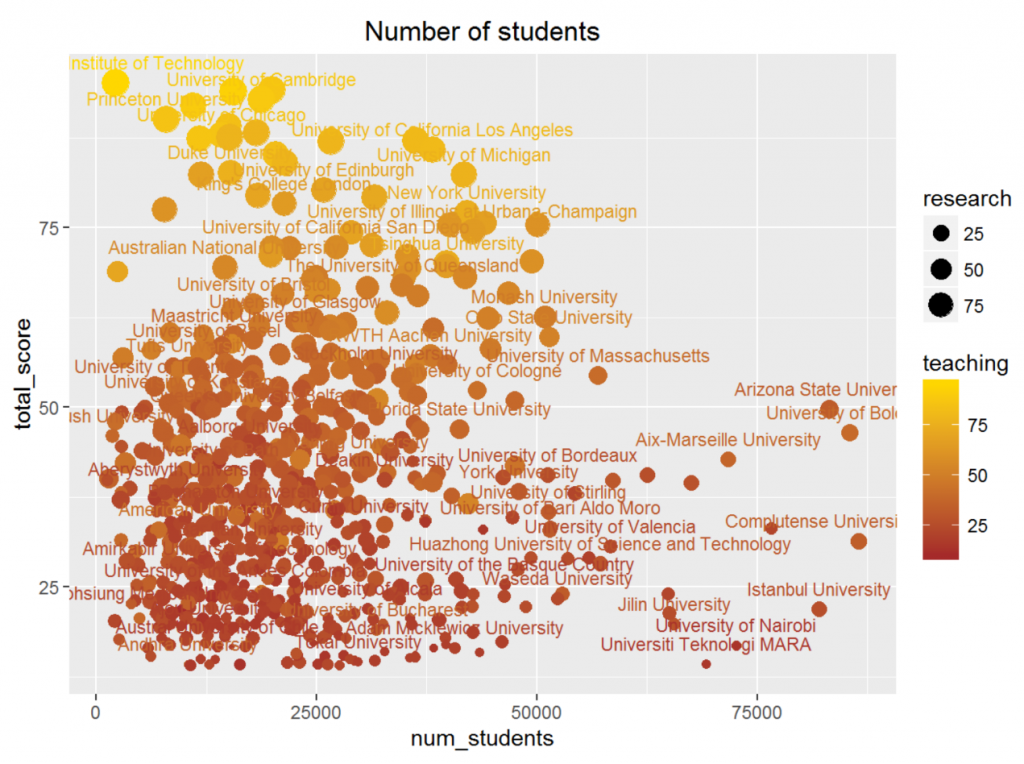
所以我们可以得出结论:如果一个大学学生数量非常庞大,那么这个大学很难是一所非常优秀的学校。但如果一个大学的学生数量处于一个正常的量级,那么我们无法对这个学校的水平下论断。
3.3.2.2 生师比
生师比与教学质量有很高的负相关性(-0.20),这也符合常理:学生太多的话老师很难顾及到所有人,教学水平也会有所下降。
同时,对教学水平的拉低也导致了总分不会太高,但这里的相关性并不是很明显。
下图是生师比的散点图,可以发现,生师比较高的大学水平也不会太高,而且部分的学生数量非常多。但对于生师比正常的学校,我们也无法对学校水平下结论。

所以,我们得到了和学生数量类似的结论:生师比大的学校水平不会高,生师比正常的学校水平难以判断。
3.2.2.3 国际生比例
国际生比例与几个体现水平的重要指标都体现出了很高的相关性(除了收入之外)。这可能是因为想要出国的学生大部分还是那些本国比较优秀,想要去更优秀的大学深造的同学,所以选取的大学水平也相对较高,因而产生了如此高的相关性。观察下面的散点图可以发现,水平较高的大学国际生比例都不会太低,这也一定程度上支持了我校致力于提高国际化水平的举措。
除此之外,国际生比例与必应普通搜索的数据有一定的相关性(0.33),这一方面是因为国际生比例高的大学水平高,但这并不是唯一因素,因为它与学术搜索的相关性并没有这么高(0.17),所以另一方面也可能是因为国际生容易产生更多的新闻,从而增加了检索数。同时,我们还发现与必应搜索的相关性远高于百度(0.16),这可能是因为英语是现在使用的世界语言,因而产生的新闻更多地以英语为载体,而以中文为主的百度就会在信息上出现一些疏漏了。
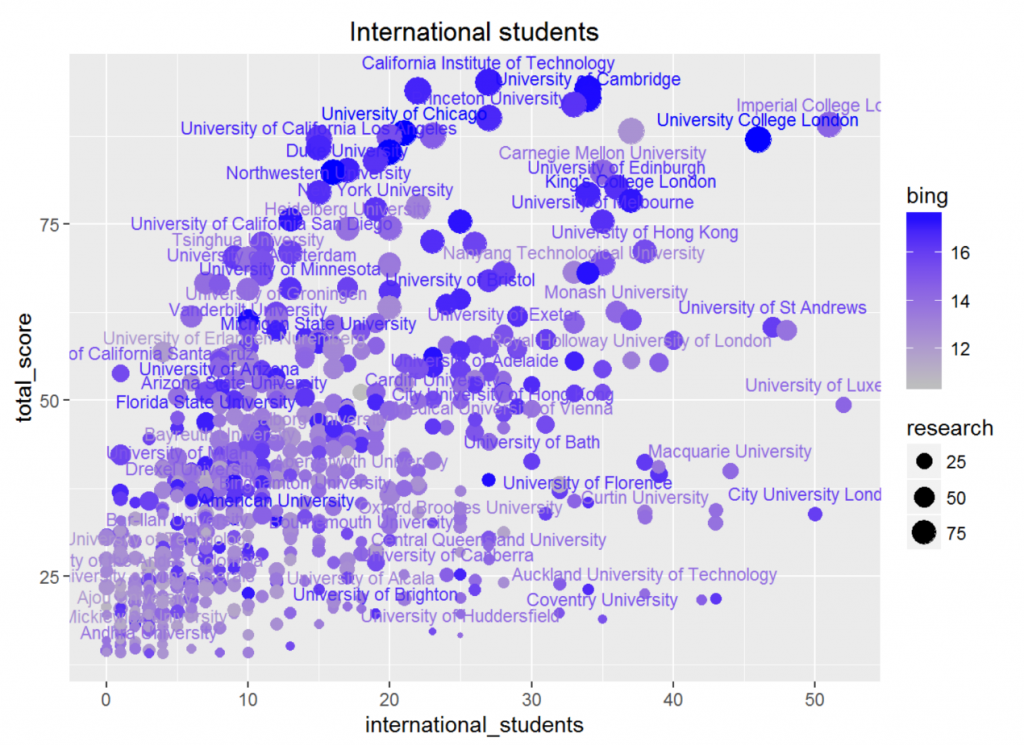
所以,我们得出结论:国际生比例是反映学校水平的一个重要指标;国际化水平较低的学校不太可能是顶尖大学;国际生比例与必应普通搜索的数据有一定的正相关性。
3.2.2.4 搜索引擎数据
几个搜索引擎相关的数据(百度、必应普通搜索、必应学术搜索、论文数)都与总分有较高的相关性,这说明搜索结果能够一定程度上反映学校的水平。
在这之中,百度的搜索数相关度最低(0.26),这一方面是因为百度作为一种综合搜索,其结果并不一定能反映出学校的学术水平,比如学生数多可能导致搜索结果庞大。另一方面,百度作为一个中文为主的搜索引擎,搜索英文学校名的效果会次于诸如必应、谷歌这样的搜索引擎。

从散点图可以看出,个别搜索条目数过低的学校确实水平太次,但其余的学校页面相差数并不多,但水平却有很大的差别。所以,百度数据并不能很好地作为我们判断学校水平的一个指标,只能帮助我们排除掉一些比较差的学校。
相比而言,必应搜索的相关性就高了不少(0.44),这和语言可能存在一定联系。
另一方面,我们也在思考综合搜索与学校水平相关背后的原因,知名校友可能是关键的因素之一。名人所占据的条目显然远多于常人,同时,如果新闻中涉及到了他毕业的院校(尤其是在毕业于名校的情况下),那么就会增加该学校的搜索条目。遗憾的是,我们并没能找到校友相关的数据来印证我们的猜想。
观察下面的散点图,我们几乎可以看出总分与搜索数的正相关关系。但是,顶尖大学和一些水平不高的大学搜索数相差也并不太多。因此,必应普通搜索的数据也不能非常好地满足我们的要求。
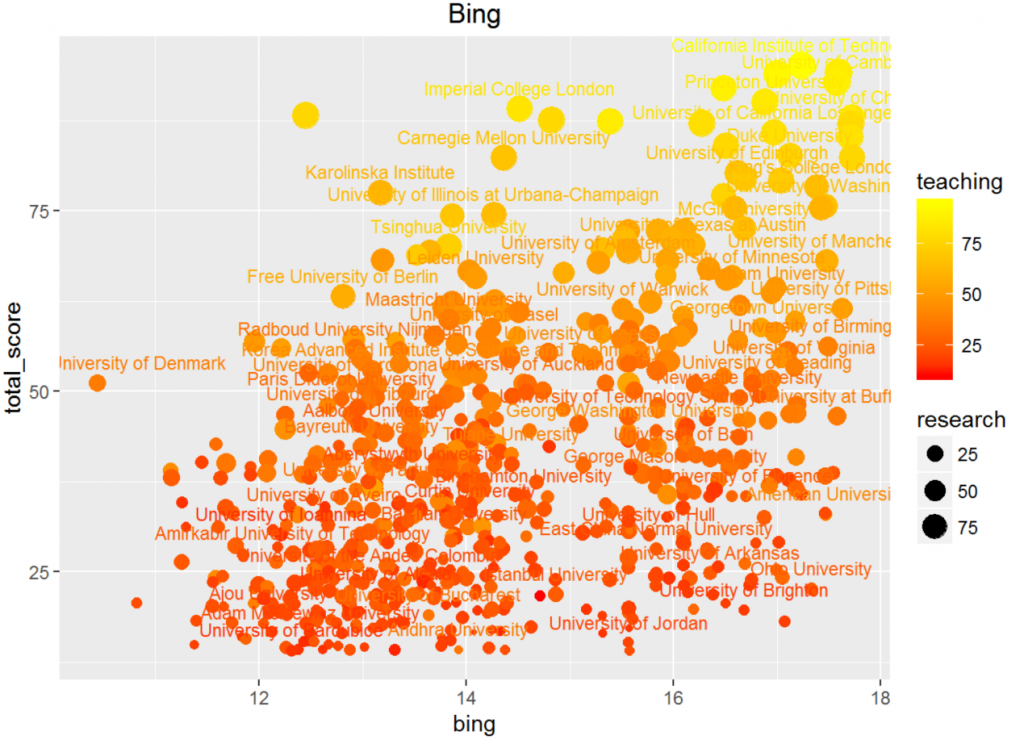
必应学术和论文数与总分的相关性更高(分别是0.50和0.62),这一方面是因为学术水平是一个学校重要的硬指标,同时也为Times所重视,但更重要的是,这个指标的人为判断误差也是最小的,哪个学校的学术水平高我们可以轻易地从数据观看得出。
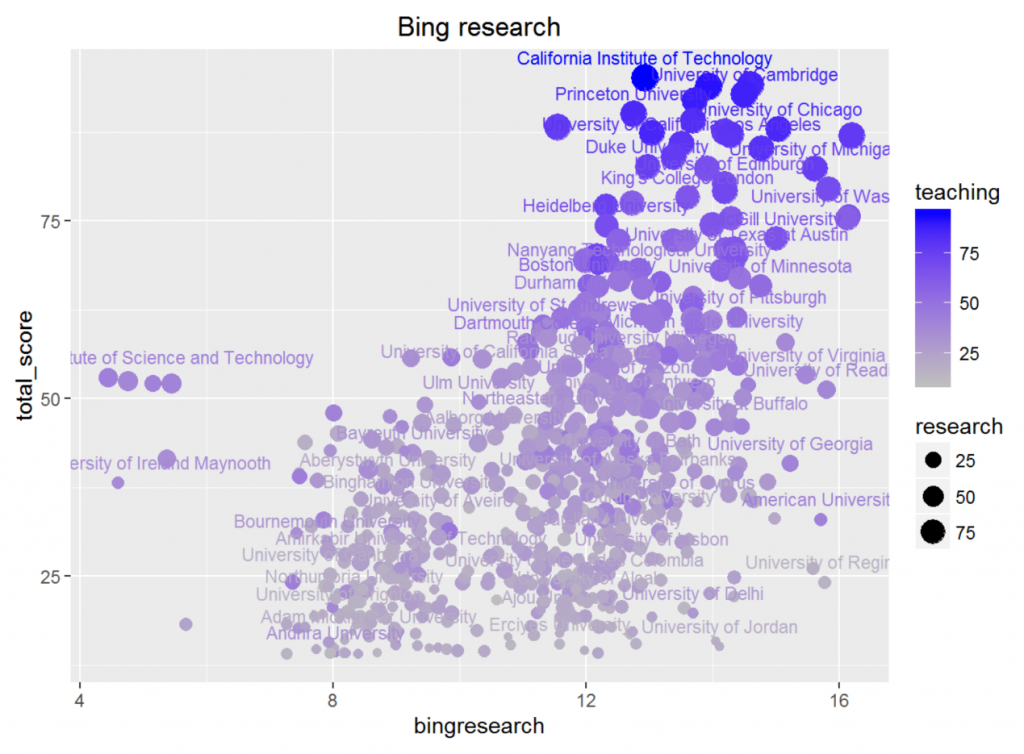
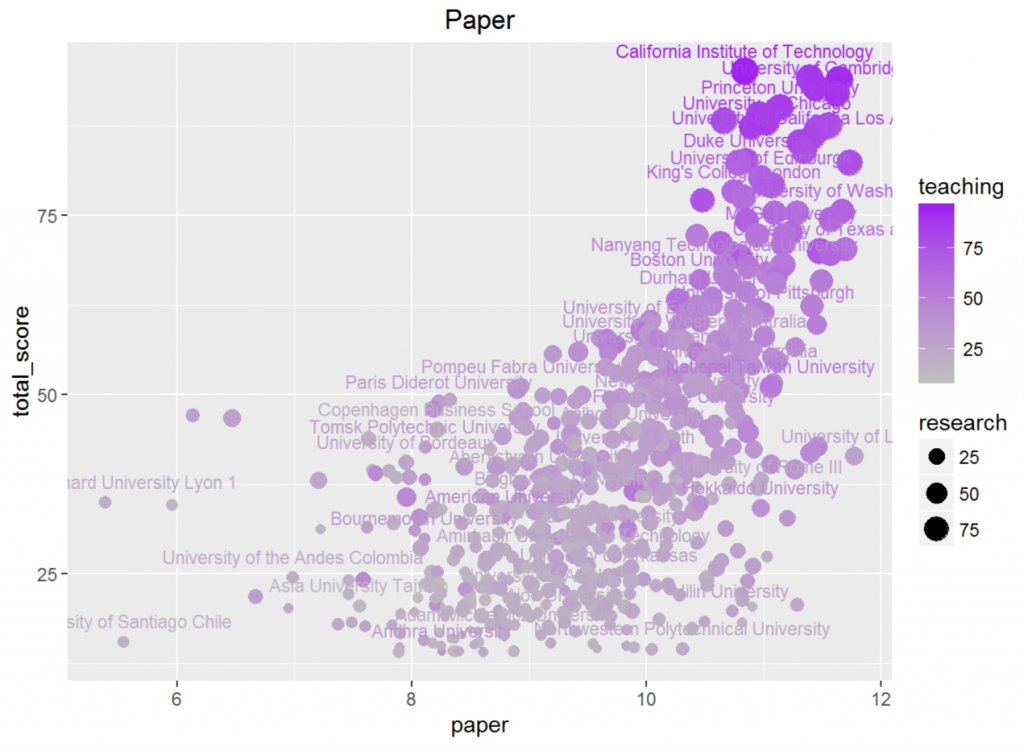
观察散点图可以发现,对于搜索数或论文数比较低的数据,我们不能判断出学校的水平,因为水平比较低的学校很难产生什么学术贡献。但对于相对较好的大学,这两组数据都有着非常明显的线性关系,这说明它们是我们判断顶尖大学水平的重要指标。
相较而言,论文数比页面数效果更好(顶尖学校与其他学校的搜索数差距更大),这与爬虫部分中对方差进行分析产生的结果一致。
所以我们得出结论:论文数是衡量顶尖大学的重要指标;搜索数较低的大学很难有很高的水平。
我们从Kaggle获得了各种排名之后,想能够找到一种直观展现大学排名地区分的方法。之后的大学排名数据可视化全部基于Times2016世界大学排名。这里我们用R语言画出大学排名在各个国家中的分布以及美国大学排名的各州分布如图所示。(注:之后一律用“top大学”一词代表Times2016世界大学排名中前800的各所大学)
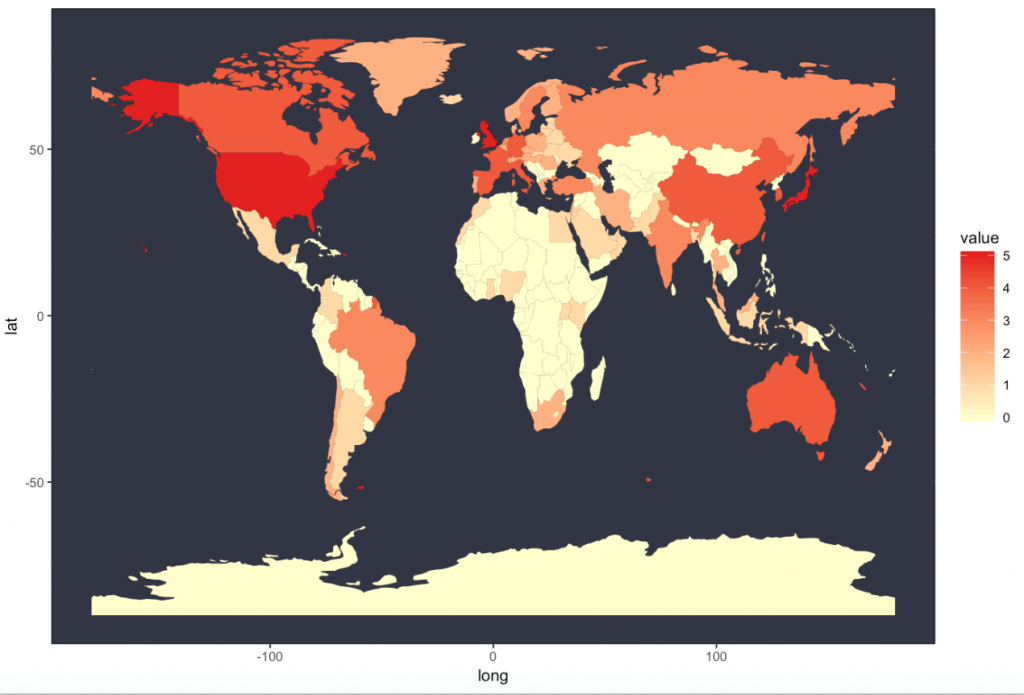

画出top大学在世界、美国的地区分布不仅仅只是想要直观展现出我们所研究数据的特点,还希望借助这种直观的可视化该我们启发,做一些更有探究性的工作。我们希望把视角扩大,结合其他的一些辅助数据,看看大学排名从直观上是否和其他的一些统计指标相关,并且试图使用机器学习的一些简单方法研究顶尖大学数量的世界分布是否能够划分出各个国家的经济水平与地理位置。最终我们选择了犯罪率、道路安全、国家旅游开销三个维度的数据。
4.3.1 国家经济水平的分类器
我们认为top大学数量或许可以很好地预测国家经济水平状况。于是我们尝试通过175个国家的top大学数量(很多为0)来预测这些国家是否是G20国家。
我们分别尝试支持向量机和BP神经网络的方法进行分类。结果如下
(1)支持向量机(输入变量为top大学数量)

(2)支持向量机(输入变量为top大学数量、犯罪率、旅游开销、交通死亡率)
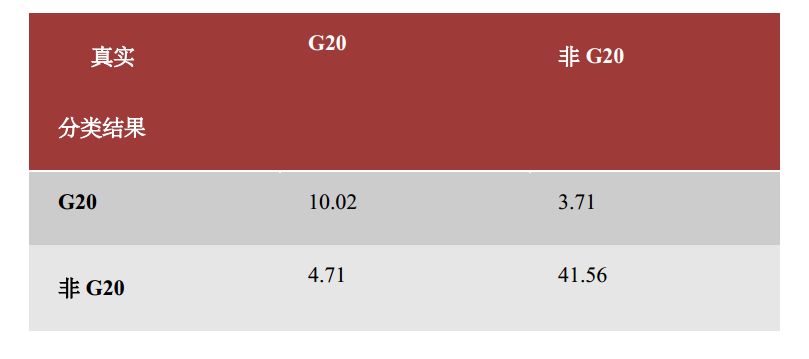
(3)BP神经网络,输入变量:top大学数量、犯罪率、旅游开销、交通死亡率

我们发现采用线性支持向量机得到的效果最为理想,在仅仅以top大学数量作为输入时,最后已经能够以较高的正确率区分出国家是否属于G20了。加上其他的几个数据集带来的额外信息(维度)之后,错误率进一步降低,第一类错误率为32%,第二类错误率为8%,总体错误率为14%。可以认为top大学的排名能够较为有效地粗略划分出国家的经济水平。
4.3.2 国家地理位置的非监督划分
Top大学数量的地理分布启发我们通过这一分布来预测各个国家的地理位置情况。我们尝试通过top大学数量来预测各个国家属于六大洲中的哪一个(除去南极洲)。换句话说,我们希望考察top大学数量数据相似性与国家地理位置相似性之间的关系。
我们选用的方法是K-means聚类。但是直接聚类的效果并不理想,数据分布过于不均匀,因而我们先通过主成分分析降维,然后进行聚类。最后得到了如下的一些结果
(1) 我们首先选用所有维度,进行主成分分析降维至5维,聚类(n=5)得到下图:
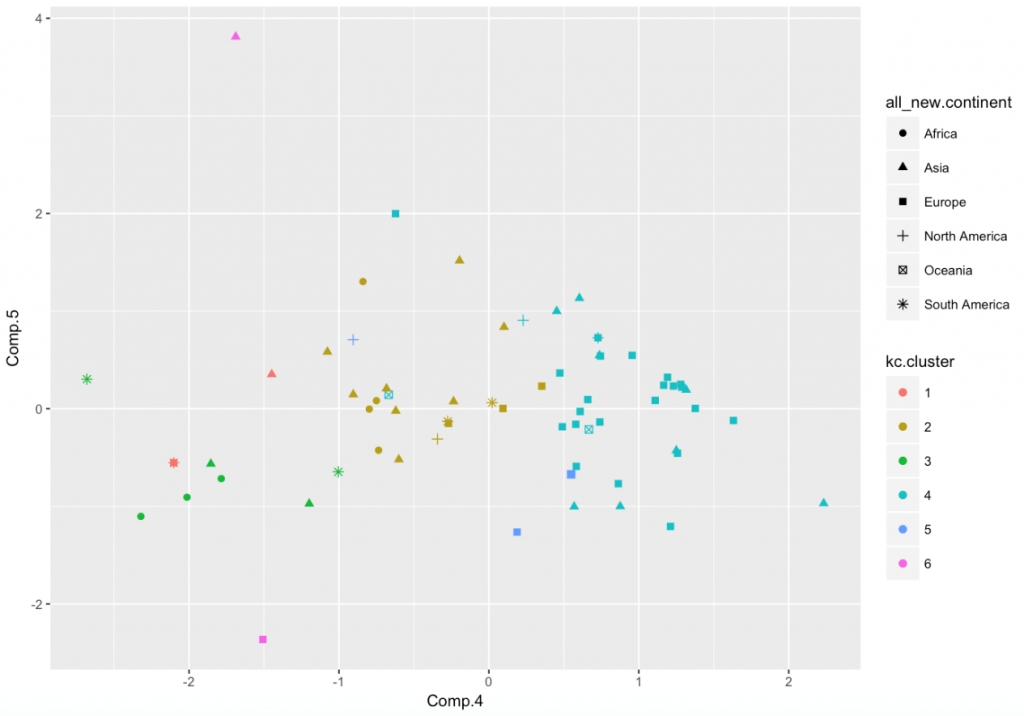
我们认为这一结果颇具解释力。左下角的绿色类包含了部分的南美洲国家、非洲国家中的一半以及几个亚洲国家,褐色类包含了多数的亚洲国家和少数欧洲、非洲国家,整一类很偏向于亚洲。湖蓝色类包含了几乎所有的欧洲国家,且很少有其他洲,几乎能够很好地提取出欧洲一类。南北美洲国家却被完全打散,没有任何的相似性。由此可见,top大学不为零的国家中欧洲国家相似性最高,亚洲也有明显的相似性。但由于72个国家中南北美洲国家数量较少,并没有呈现明显的相似性结果,非洲国家都较为靠近左下角,有一定相似性。
(2) 我们随后选用和top大学数量相关的6个维度,进行主成分分析降维至4维,聚类(n=6)得到下图:
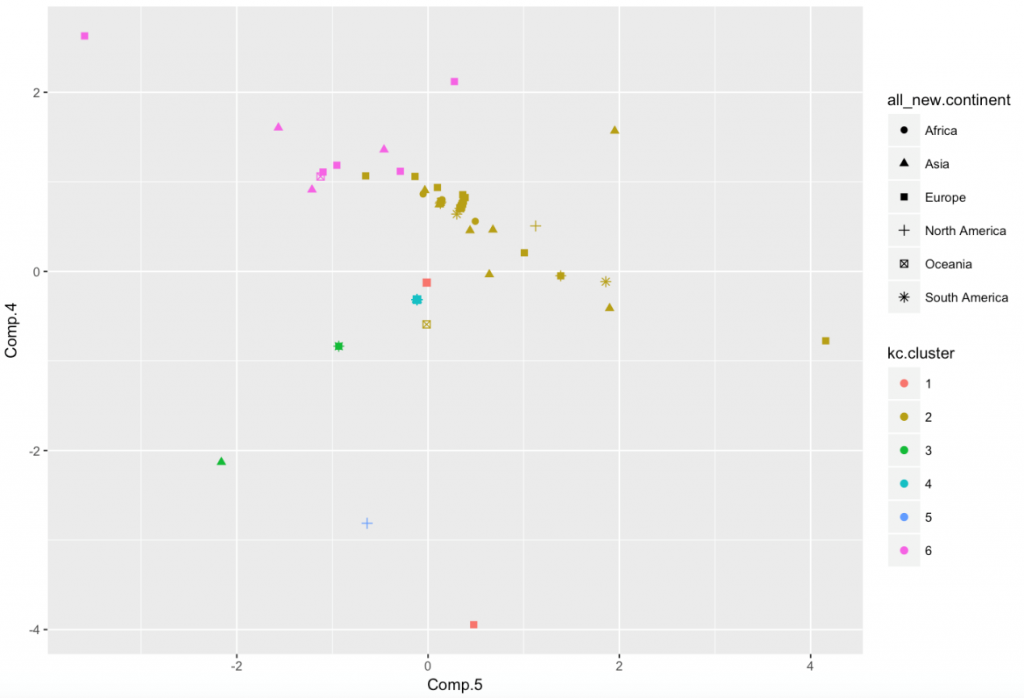
由图可以看出仅仅采用国家所含top大学数量无法得到较为好的地理位置划分,大部分国家的数据聚集到了一起。这不禁让我们怀疑之前聚类结果中能够划分出地理位置的最主要因素是否和top大学数量没有关系。因而为了控制变量我们设计了比较试验,也就是——除去top大学数量相关6个维度外选用其他维度,进行主成分分析降维至3维,聚类(n=6)得到下图:
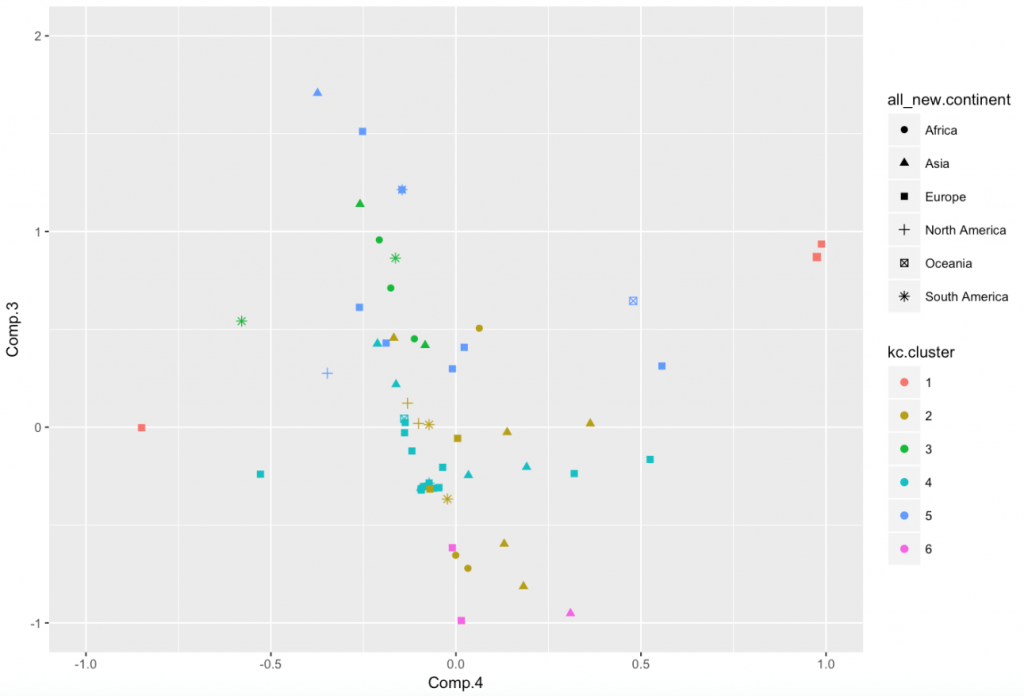
不难看出在缺少了top大学数量之后,聚类得到的6个类别完全没有任何特点,每个类别都比较均匀地含有各洲的国家。因此通过对比实验,我们间接地验证了有top大学数量的数据集在度量国家地理位置相似性方面有着明显的提升,top大学数量的相似性能够有效地帮助度量国家地理位置的相似性。但是单独的使用top大学数量进行地理位置度量却也无法得到很好的效果.
5.1.1 必应搜索分析
5.1.2 相关性分析
5.1.3 数据可视化与直观数据分析
5.2.1 考虑相关因素的大学排名
由于时间有限,这一块我们处理好了数据却还没来得及继续往下做。但是我们已经对这一块有了初步的设想如下:
如果仅靠网页条目数排名,单个大学条目数肯定是不行的,需要综合考虑相关的条目数。综合条目数相当于一个矩阵,我们需要对这个矩阵进行一个处理。
在相关矩阵里,我们可以根据一些现实情况对条目数进行一定的修正。例如,考虑到建校时间,某些大学的条目数不能真实反映其水平(例如刚建校的南方科技大学);例如,考虑到地理位置,相关条目数需要做一定的修正(例如A和B相差比较大,仅仅因为地理位置相近于是条目数也会相对多一些)等等。
继续这个课题本身可以是一个挑战杯项目,有很多可以做的事情。
5.2.2 从Bing学术上挖掘大学的专业分类
Bing学术对于每一个学校,还提供了“相关领域”和“相关机构”两个列表。据此我们可以得出一个学校的优势专业,从而将学校分为综合性、文理科、理工科等几类。有了大学的分类后,相关性分析可以在各自领域内进行。还可以在Bing学术中直接搜索某个领域的名字,得到这个领域的总论文数,以去除不同专业的特点对于论文数的影响。
5.2.3 寻找相关性分析的佐证
在相关性分析的过程中,我们通常都是对存在相关性的数据结合常识进行推断,但是除了分析男女比与收入关系时进行了偏相关性检验,其他的分析我们并没有寻找进一步的证据支撑。
比如我们在分析百度、必应数据时提到了校友的可能,因此,我们需要结合毕业生的数据进行分析,证实我们的猜想。再比如我们对STEM的选取也不精确,为了提高我们推理的可信度,我们需要寻找学校所属类型的数据。
现有的数据显然不足以支持我们进行进一步的分析,所以,我们需要使用爬虫等手段进行进一步地数据获取。
此外,男女比与国际化水平的联系并没有找到很好的解释,还需要进一步地探索。
5.2.4 从相关性到因果推断
本文的分析基本都是基于相关性进行的分析,对指标与大学排名之间的关系进行了推断。
但是,相关性与因果关系并没有必然的联系:有因果关系并不一定相关,有相关性更不一定存在因果关系。尽管相关性已经足以帮助我们对大学水平进行判断,但是,我们也关心指标与大学水平之间的因果关系。
但是,因果推断本来就是一件非常困难的工作,尤其是对于这个问题,我们很难设计出随机化的实验,潜在的变量也数不胜数。如何进行因果推断,或者甚至能不能进行因果推断,是一个值得探索的问题。
5.2.5 直观数据探索性工作展望
数据的地理分布所带来的启发性工作还远远没有被探索完。首先,我们仅仅完成了一部分对于顶尖大学国际分布的探索,而没有考虑可视化费尽周折才完成的美国顶尖学校的分布。这一部分的可挖掘性甚至要更强。在这一更小的区域里,更多的数据挖掘想法被赋予了可能:与美国大选、NBA球队战绩、甚至是气候、海拔的相关性与相似性度量都很可能得出非常有意思的结果。与此同时,在世界大学分布中我们还设想能够探索一些学科排名靠前大学的地理分布,例如顶尖商学院多的地方是否是大国家的大城市?顶尖理学院是否又地处较为偏僻?工科学校强的国家其GDP是否以第二产业为主?文科发达的学校是否处在历史更悠久的地区?这些都是在未来等待我们去探索的内容。
本文选自清华大学统计学研究中心开设的统计学辅修课程《数据科学导论》优秀学生成果
小组成员:
姜紫煜(清华大学工业工程系14级本科生)
谢禹晗(清华大学工业工程系14级本科生)
高代玘(清华大学工业工程系14级本科生)
王 璐(清华大学工业工程系14级本科生)
指导教师:俞 声
我们常说“一见钟情”,但又是什么因素导致了一见钟情呢?哥伦比亚大学的一项基于一次“快速约会”结果的实验数据给我们提供了丰富的研究背景。利用一些数据科学中基本的数据处理手段以及R中的可视化工具,我们获得了许多有趣的结论。
此数据集原本有195列数据。但是考虑到我们的目标是预测两人配对成功的概率,其实大部分变量并没有意义。因此,我们对变量进行了一定的筛选。首先,我们通过常识选出了以下69个可能存在相关性的变量:
得到的这69列数据中,有一些数据有所缺失,因此进行了针对性的数据清洗。
(一)同伴对该参与者6项指标的打分的缺失
我们通过观察,发现6项指标不是同时缺失的。而如果直接删除所有带空数据的样本,就会删掉1347条数据。考虑到一共只有8378条数据,我们选择采取填充的办法。 尝试用同一轮中其余9个人的平均值来对第10个人的缺失值填补,但发现均值通常不是整数。而在后续的决策树与分类的过程中,可能需要打分作为factor,因此最终选择取其余9个人的中位数来填补。
(二)iid(该参与者在整个活动中的中编号)的缺失
在总结中位数时,我们发现总行数比iid最大值少1,没有iid伪118的参与者。因此在填充时,要注意用iid而非行数匹配。
(三)id(该参与者在该轮中的编号)的缺失
通过summary函数发现id有一个缺失,其对应的iid为552。列出所有iid为552的样本,发现id应为22。因此在缺失处填上22即可。
(四)参与者自己对自己5项特质的打分的缺失
观察发现,这5项特质的打分总是同时缺失的,说明这是由于在该轮中没有要求参与者对这个项目进行打分。通过计算,发现一共只有105个样本缺失该变量,因此我们选择删除这105个样本。
(五)参与者的年龄与同伴的年龄的缺失
通过对比iid,发现缺失年龄的参与者与缺失年龄的同伴恰好都是同一批人,因此无法对应填补。又因为用年龄的中位数补空可能造成极大的误差,而实际缺失年龄的样本又不是很多,因此,我们选择删除这一部分样本。
首先,我们使用一些基本的统计量及图表来描述参加这次“快速约会”的志愿者的年龄、性别、居住地、教育及工作背景等信息。
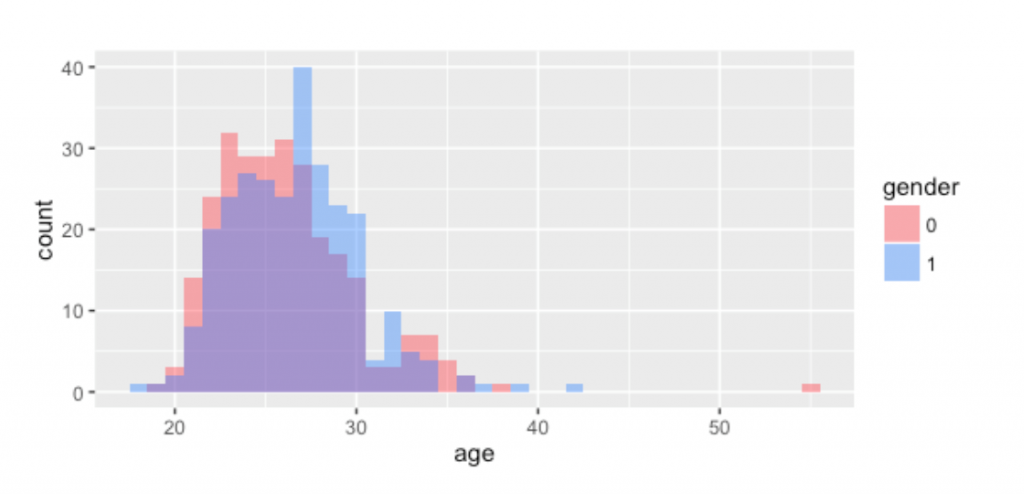
(一)年龄和性别
下图以直方图的形式描述了各个年龄段参加约会的志愿者的年龄组成。我们可以看出(1)参加约会的女性和男性的年龄分布基本是相似的,(2)志愿者的年龄大致分布在20岁~30岁之间。
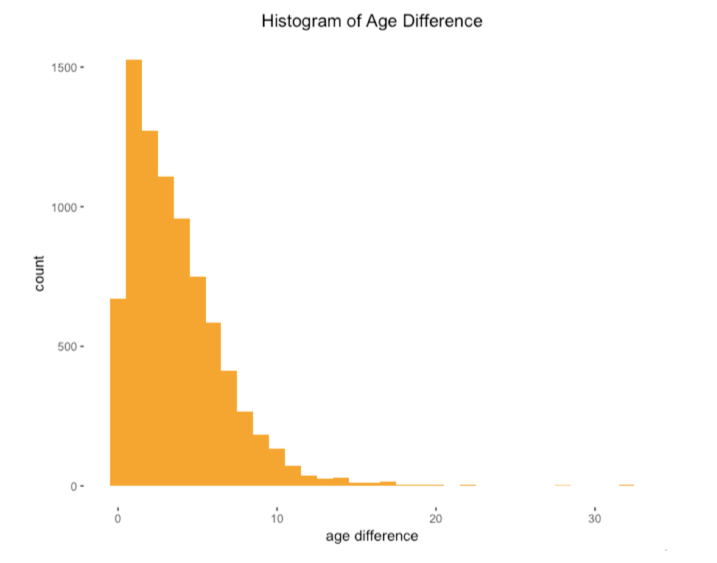
基于常识我们猜测年龄差异可能对约会产生较大的影响,所以我们决定绘制直方图来展示配对成功的参与者的年龄。从图上我们可以看到参与者之间的年龄差在1岁到5岁之间的时候配对成功率较大。但这项研究的大部分参与者是年龄相仿的大学生,所以我们还不能得出年龄相近则配对成功率大的结论。
(二)志愿者的出生地分布
在这个数据集中,大多数的志愿者都来自美国,为了显示方便我们仅仅绘制了美国的部分地图以反映志愿者出生地分布(地图由maps包绘制)。
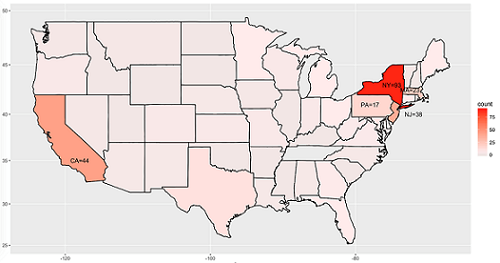
图中可以看出,人数最多的五个州依次是纽约州、加利福利亚州、新泽西州、宾夕法尼亚州和马萨诸塞州。
(三)民族背景
下图以直方图的形式展示了参加约会的志愿者的种族组成。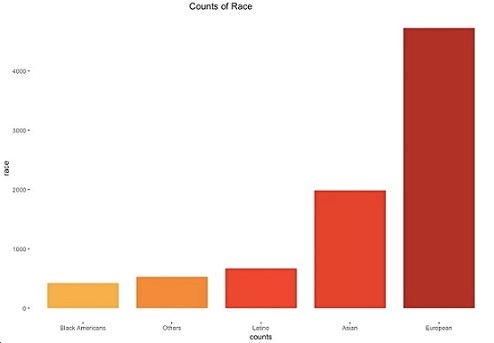
同时,我们还用网络图的形式呈现了配对成功的情侣的种族背景(由R的iGraph包绘制)。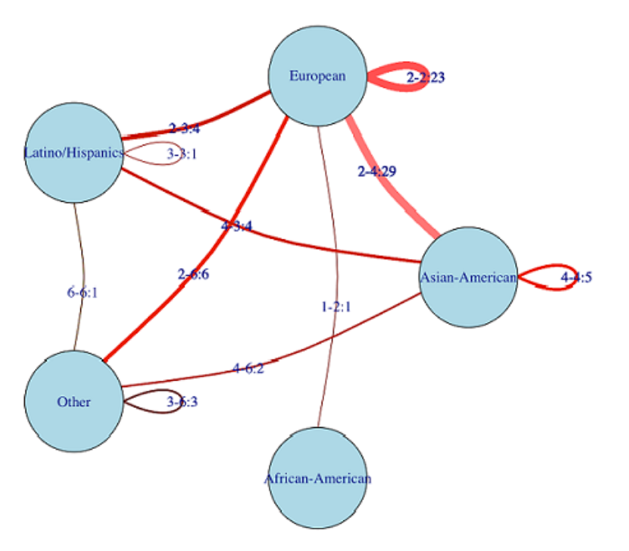
种族背景
图中以圆圈和线的形式标注了各对情侣的种族来源。
(四)职业与教育背景
首先,我们根据志愿者填写的职业信息合并同类职业,并画出频度直方图。我们发现“business”出现的频率最高,符合很多人在经商的现实。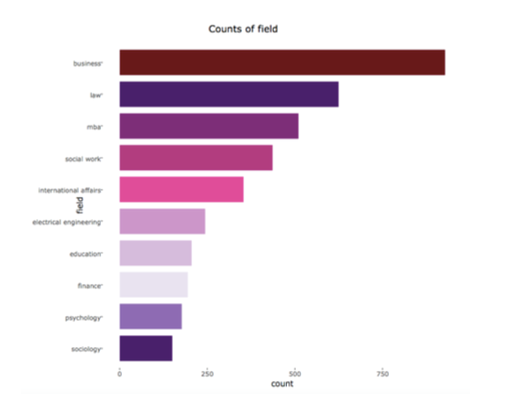
数据集中的职业、教育信息多以非结构化文本的形式呈现。为了更好的展现这一信息,我们采用了词云图的形式体现志愿者们的教育背景(主要为本科就读的学校)以及从事的职业和相应的频率。


从图中可以看出,许多参加本次“快速约会”的志愿者来自美国名校,从事行业也多为法律、商业、学术界等。可谓是“高帅富”、“白富美”也需要担心人生的头等大事啊!
(五)可视化交互:R-Shiny Dashboard
我们选取R中用于可视化的Shiny Dashboard 包将我们的结果进行可视化处理。选取Shiny Dashboard作为可视化工具的原因如下:
为了获得较为合理的文字处理结果,我们首先用R的分词处理功能获得了我们感兴趣的关键词,解决了第一种问题;对于高频词我们使用了正则表达式检验可能发生的错误输入,还利用数据挖掘的概念探寻可能存在的相关连词汇,以减少上述第三种错误发生的可能。
下图展示了影响配对成功的重要因素的相关性,冷色调代表正相关,颜色越深代表相关性越大。我们发现“喜欢程度”这个因素与“兴趣爱好重合度”,“外在吸引力”,“幽默程度”都有很强的相关性,为后续模型的变量选择提供了依据。此外我们发现,作为评判方的志愿者在“聪明程度”和“野心程度”、“真诚度”,“幽默程度”和“兴趣爱好重合度”、“外在吸引力”也有明显相关性。
我们用决策树的方法尝试找出影响配对搭档的决策的最重要的影响因素。我们使用清洗好的数据,排除部分无效信息后进行建模。我们发现是否配对成功很大程度上取决于搭档的“喜欢程度”,这是符合常理的。但由于“喜欢程度”是一个包含很多复杂因素的变量,所以我们对模型进行优化,去除类似“喜欢程度”这样的可能与其他变量有很大相关性的复杂变量。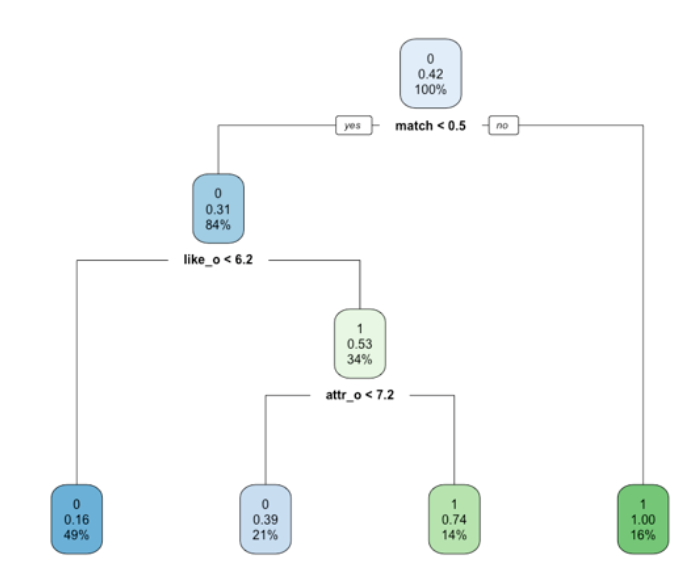
调整后,我们得到下图所示的模型。搭档对于志愿者吸引力的评分很大程度的影响能否配对成功。此外,适度的幽默也有助于“牵手”成功。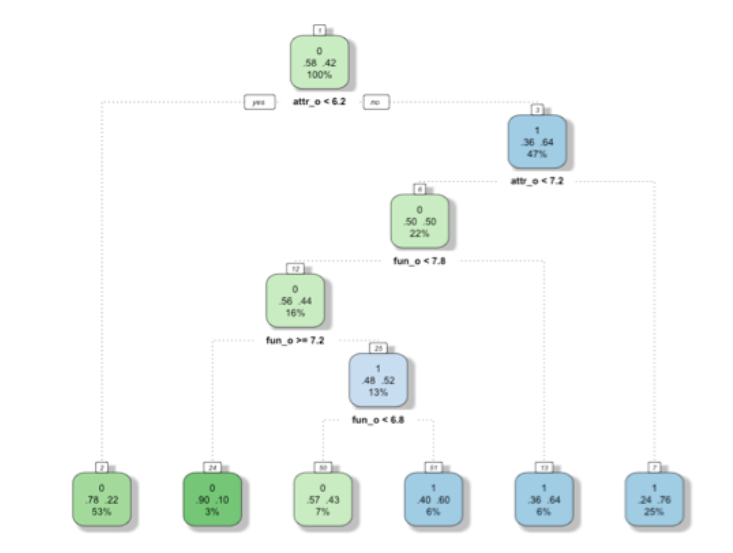
为了预测两个参与者配对成功的概率,需要将二者的特征和相互关系同时放入模型中进行预测。因此,我们将两个参与者的对于6个特质互评的分数、及分数的差的绝对值同时放入决策树模型中。
可以发现,最重要的影响变量依然是“外在吸引力”和“幽默程度”。但与之前模型得出的结论不同的是,“兴趣爱好重合度”也成为了重要的影响因素。这很符合我们的常识,及两个人只有“三观一致”的时候才更容易在一起。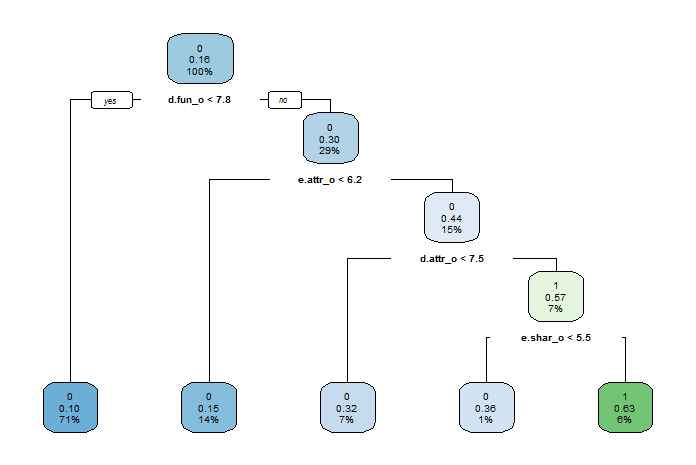
我们通常认为两个人打分的差异性也会有影响,即各方面特征都较为相近的人才更容易在一起。但是这一点在模型中却并没有体现出来,各方面打分的差的绝对值最后没有出现在决策树模型中。我们认为这可能是由于两人的差异不能简单地通过差地绝对值来体现,可能有更复杂地表示形式,因此导致变量设置不当。
运用以上的决策树模型,我们希望对还未参加活动的人在该活动中能否找到意中人进行预测。但是这只能预测搭档能否看上这个参与者,而不能预测两人能否最终牵手成功,因为搭档的情况还未知,不能保证此参与者也能看上他的搭档。
通过决策树模型,我们发现一个人认为他人对自己的看法与他的搭档最终是否看上他了并没有绝对联系,这意味着人们认为他人对自己的认知通常是错误的。因此,我们假设一个参与者可以通过以往的经验得到他人对自己的打分,并用这个打分进行预测,判断自己有没有必要去参加一场快速约会。
以下两个例子说明了不同的预测结果:
我们的决策树模型提供了如下几个有趣的结论:
总的来讲,虽然“颜值”(attractiveness)的确对约会是否成功起到了主要作用,我们仍然无法忽视个人爱好(share)以及幽默感(fun)的重要性。所以,对于希望找到另一半的各位,不仅要维持一个良好的外部形象,追求内在也十分重要哦!
本项目中曾使用过的研究手法和展示手段:
本项目使用R语言进行数据处理和展示,主要使用的扩展包如下:ggplot2& ggplotly (数据可视化绘图)、shiny(交互界面搭建)、igraph(网络图)、maps(地图)、wordcloud2(词云图)、rpart(决策树建模绘制)
参考文献:https://www.kaggle.com/annavictoria/speed-dating-experiment(数据集来源)
参考书目:Winston Chang,《R数据可视化手册》. 人民邮电出版社
Company Information: The Biostatistics Branch (BB) is an intramural research program within the Division of Cancer Epidemiology and Genetics (DCEG) at the National Cancer Institute (NCI). BB statisticians develop statistical research programs and actively collaborate both in cutting-edge studies of genetic, lifestyle, and other environmental causes of cancer as well as in studies of cancer prevention, descriptive and clinical epidemiology. Statistical research is typically motivated by challenges encountered in DCEG studies.
Position Title: Postdoctoral Fellowship in Biostatistics
Duties and Responsibilities: The Biostatistics Branch is seeking a Postdoctoral Fellow to work on areas of statistical genetics and general biostatistics methodologies.
Position Qualifications: Strong candidates from statistics, biostatistics, or bioinformatics doctoral programs are encouraged to apply. The stipend is commensurate with training and relevant research experience.
Please contact Dr. Kai Yu (yuka@mail.nih.gov) for questions about the position. Further information about the Biostatistics Branch and Division may be found at: http: http://www.deceg.cancer.gov. These positions will remain open until qualified applicants are found.


清华大学统计学研究中心博士后招聘
2014年5月16日,清华大学校务会议批准成立清华大学统计学研究中心。中心的发展目标是:“建立高水平师资队伍,开展高水平学术研究,增强与相关院系单位的交流与合作,尽早在清华建成国际一流的统计学科”。中心为独立的校级学术机构,行政事务挂靠工业工程系。根据学科发展需要,我们面向海内外诚聘优秀人才加盟清华大学统计学研究中心。
申请人应具备的基本条件:
1. 应届毕业博士或者博士毕业2年之内
2. 品学兼优、身心健康、年龄不超过35周岁
3. 在本专业领域具有较好的研究基础,有相关论文发表
4. 具有独立开展科研的能力,对学术有追求和钻研精神
5. 其它要求参见清华大学博士后网站:
http://postdoctor.tsinghua.edu.cn/bsh/index.jsp
岗位待遇:
按照清华大学博士后管理办法执行,根据工作能力和业绩发放奖励。