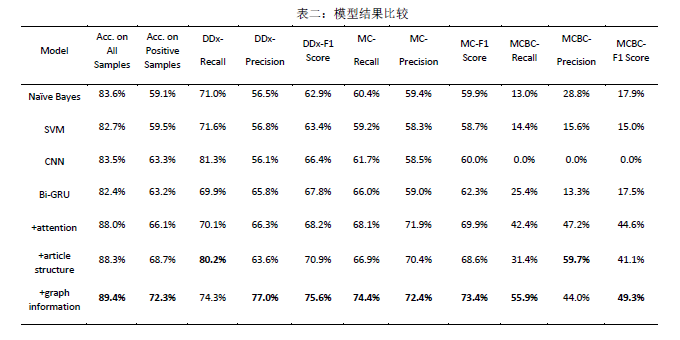
序贯蒙特卡洛方法作为一种重要的计算工具,被广泛地应用于各个领域中,其中重抽样是序贯蒙特卡洛方法中重要的一步。同时重抽样也是一把双刃剑:一方面,重抽样可以保证序列样本保持一定的有效样本量;另一方面,重抽样会引入新的随机性,使得估计的误差变大。重抽样有着很多种不同的选择,例如Bootstrap重抽样,分层重抽样等。清华大学统计学研究中心邓柯副教授团队与哈佛大学统计系刘军教授团队针对不同情形下的最优重抽样问题展开了进一步研究,相关成果已在统计学顶刊Biometrika发表。中心16级博士研究生李艺超及哈佛大学统计学博士生王文槊为文章的共同第一作者。

在重抽样最优化理论的研究上,本研究的主要贡献包括:
(1)在一维情形下,证明了将样本排序后,分层重抽样在条件方差、能量距离、最优传输等意义下均是最优的。(2)在多维情形下,通过希尔伯特曲线对样本进行排序,分层重抽样的条件方差可以得到最优上界。
结合前两个结论,在序列拟蒙特卡洛方法(SQMC)的框架下,研究团队将抽样和重抽样两个部分结合起来,提出了一种新的抽样方法(Stratified Multiple-Descendant Sampling),并证明了该方法在理论上可以得到已知的最优均方误差。
相关工作建立了序贯蒙特卡洛重抽样算法最优性的系统理论,并以此为基础提出了新的、效率更高的抽样算法,在统计计算理论和应用方面具有重要的原创性贡献。