
清华大学统计学研究中心16级博士生林毓聪投稿的论文《从医学文本库中自动提取疾病关系》荣获第四届全国高校研究生统计论坛十佳论文。该论文研究的医学知识图谱构建工作是其指导老师俞声教授的重要研究方向,而疾病关系的提取工作是医学知识图谱构建的核心工作之一。该论文投稿的全国高校研究生统计论坛是全国高校学生创新统计联盟最重要的活动之一,是供统计领域在校硕博生进行学术交流的大型会议。
在医学信息学中,一个高质量的医学知识图谱是自动诊疗、辅助诊疗等现代医学人工智能工作的基础工作,而知识图谱中最关键的元素就是概念之间的关系,如[二型糖尿病][导致][体重减轻]。疾病之间的关系是医学概念的核心关系之一,但由于种种困难并未在现有图谱中建立起来。此论文致力于通过文本挖掘和机器学习的方式,通过文本数据判断疾病与疾病之间的关系,为医学知识图谱的构建工程添砖加瓦。
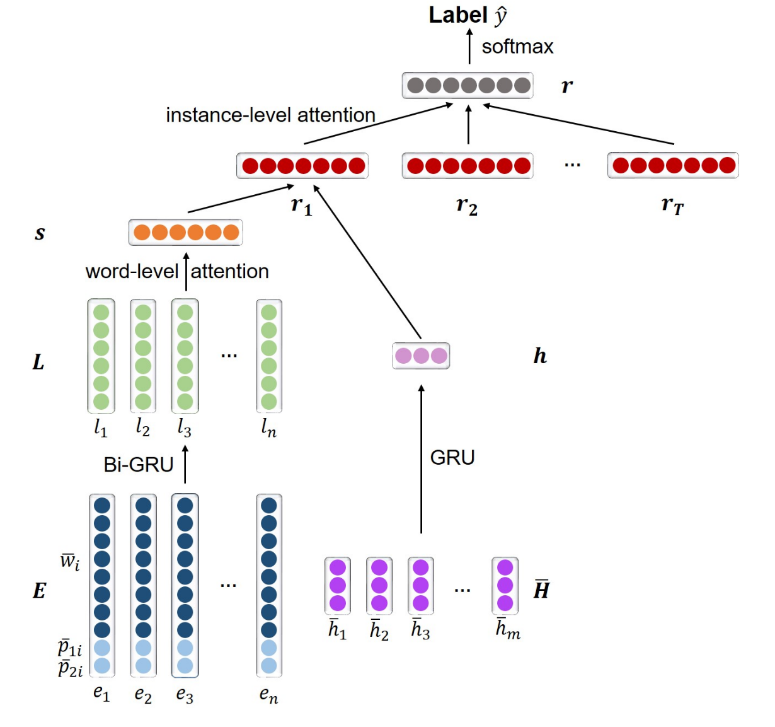
该论文通过开源医学知识网站与维基百科中医学文章作为医学文本库,扩展了关系提取的数据收集机制,从文本库中进行训练数据的采集与自动标注,并进行了多轮的数据清洗,提升样本的自动标注质量与信号强度。在模型中,论文选用含Attention机制的双向Bi-GRU模型,并加入了文章章节结构信息,并使用GRU进行自动编码,最后将同一个概念-关系三元组所对应的所有训练语句进行加权后输出。
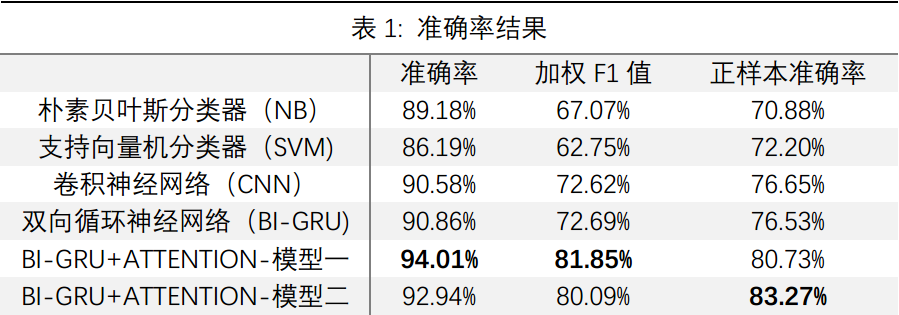
该论文在关系分类中,从准确率、加权F1值与正样本准确率三个评价指标中,均达到了远超基准模型的好结果。进一步地,论文使用模型二对无标签的疾病关系进行预测,从而挖掘新的关系。论文设定0.8作为筛选阈值,在12561个超过阈值的预测结果中抽样了200个结果使用明确的医学知识作为严格的评价标准,预测准确率达到75.5%。
综上所述,该论文至少有两方面优势。从工程层面,该论文通过数据清洗、模型搭建最终获得了关于疾病关系的高质量医学知识图谱;从方法层面,该论文对传统关系提取的数据收集方式进行扩展,并采用最适合数据形式的神经网络模型进行建模。林毓聪同学表示,这是花费近三年时间完成的工作,非常感谢俞声老师的悉心指导与审稿老师的认可,日后将会更努力的在医学大数据领域深入研究,为医学人工智能贡献出自己一份力量。













