
使用机器学习预测新的恐龙
本文选自清华大学统计学研究中心开设的统计学辅修课程《数据挖掘中的统计方法》优秀学生成果。
小组成员:
陈显:清华大学工业工程系 14级本科生
骆升:清华大学数学系 14级本科生
指导教师:俞声
就我们所知,每年都有新的恐龙被发现,于是我们希望能够利用机器学习的方法,来帮助古生物学家发现新的恐龙及其图像,并且预测新的恐龙的特征和数据。
那么如何用机器学习的方法“发现”新恐龙呢?我们想到机器学习里面有一类模型叫做生成式模型,可以靠输入的图像样本来生成新的图像样本,那么我们就可以利用现有的恐龙图像生成新的、现在还没有被发现的恐龙图像了。生成式模型中最火的,便是生成对抗模型(Generative Adversarial Networks),下面简称GAN。我们就考虑使用GAN来“发现”新的恐龙了。
除了新恐龙的图像,我们还希望能够通过控制用来生成新恐龙的图像样本,来控制得到的新恐龙的属性(如身高、食性等),所以我们挑选好想要的属性,使用聚类将具有类似属性的已知恐龙图像挑选出来,并放入GAN里跑。
在得到新恐龙的图像后,我们使用图像识别,从图像中获取恐龙的一些属性(如食性、生活地区等),与挑选图像时使用的属性相比较。同时,我们希望能得到其他属性,如恐龙的身高,因此我们将从图像识别中得到的恐龙属性,放入机器学习的回归和分类中,发现最后的结果是无法预测,也就是说光从图像中无法获取恐龙的身高体重等数字的信息。
GAN原理简介:
相当于有两个人,生成者负责生成图片,区分者负责区分图片。两人互相较量,互相训练,当生成者生成的图片与输入的样本无法被区分者区分出来的时候,我们就认为生成者生成的图片已经可以“以假乱真”,也就是说,我们认为此时GAN已经可以生成新的样本了。
我们认为,通过GAN生成的图片中可能会有未发现的恐龙,通过对这些图片做图像识别,就可以预测出这些未发现的恐龙的特征。
收集数据:
我们主要使用python编写爬虫从互联网上搜集数据
1、 获取所有恐龙的名单
在www.dinosaurpictures.org这个网站上就已经可以得到1082种恐龙的名单了
2、 获取恐龙图片
2.1 在www.dinosaurpictures.org这个网站上我们可以找到总共九千多张恐龙图片,并且每张图片还能带有恐龙的名字作为标签
2.2 在www.newdinosaurs.com这个网站上我们可以找到总共六百多张恐龙图片,每张图片也有名字作为标签 
2.3 cn.bing.com/images这是个图片搜索引擎,上面搜索每个恐龙的名字都能得到很多这个恐龙的图片,但是这个搜索引擎有着很好反爬虫机制使得我们无法把全部的搜索结果下载下来,不过每个搜索结果我们都还能下载到二十到三十张恐龙图片
最终我们搜集到了总共三万多张恐龙图片

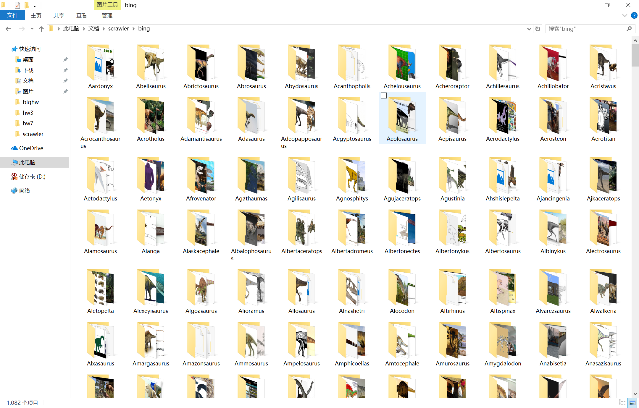
3、 获取恐龙信息
我们希望能得到恐龙的一些现有属性,因此我们从网页上抓取文本信息,主要有恐龙的生活地区、食性、身高、体长、体重、生活时期和恐龙所属的亚目、属、亚属和种。
3.1 维基百科
维基百科类似于百度百科,但是它的信息量要远大于百度百科,同时更加可靠。我们从维基百科的信息框、分类表和文章内容中抓取了如图信息,合成了一个数据集。

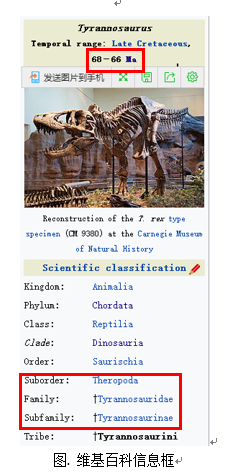
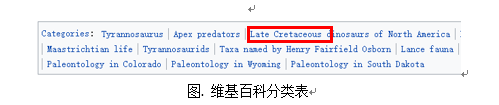
3.2 百度文库和百度百科
从百度文库中我们找到一个含恐龙属性的列表,并将它填到了数据集中。从百度百科中我们也爬取了信息框,但是由于信息框所含信息量较杂,对我们有帮助的信息较少,因此在最后我们选择放弃使用百度百科。
3.3 其他网站
我们还从国内外的一些恐龙专题的网站上找了一些恐龙的属性,挑选部分放入数据集。
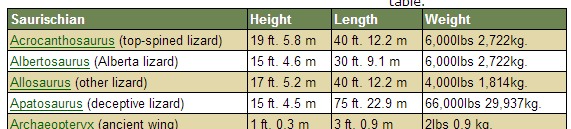
http://www/zhklw.com/
4、 预处理:
4.1 图像预处理
把黑白图剔除、把图片格式全部转换成jpg、把图片全部裁剪成统一尺寸,由于程序和硬件的限制,我们这里设置输入的图片尺寸为96*96,输出为48*48。
4.2 数据预处理
我们通过观察数据的分布,判断是否有异常点并进行去除。由于得到的数据有缺失值,我们通过已有的知识,对缺失的食性和地点作这样的判断:如果两个恐龙所属物种相同或相近,则它们是食性和地点有很大可能为相同的。通过这个规则我们填补完食性和地点的缺失值。
对于恐龙身高、体重和体长的缺失值,由于这部分数据的采集具有一定不可靠性,我们使用机器学习对缺失值进行填补。我们通过对近似密度和长高比的进行分类,将恐龙通过一定规则分为近似密度和长高比不同的几类。由于使用软件对随机森林的运用有限制,我们选择使用决策树进行分类。

使用决策树分类的规则,family为属
5、 聚类挑选样本图像
样本图像是来自各种各样的恐龙,恐龙之间不同的形态差异会成为GAN结果的不可信原因。因此我们对样本进行了聚类挑选。聚类即为通过一些属性的相似性,将样本分为几个类。我们挑选(亚洲,食肉性,鸟臀类,高5米)作为目标属性,使用聚类将具有相似属性的恐龙挑选出来,放入GAN进行识别。
其中为了保证聚类可行性,我们将亚目属性进行简单分类合并为4组亚目组,将地点属性改为各大洲大致的经纬度。
6、 运行GAN
使用带有显卡GeForce GTX 980的电脑用所有三万多张图片来跑300轮,总共花了十几个小时。我们还用聚类挑选出的的图片来跑GAN,以期望得到不同的结果。结果如下:


我们从得到的多个图像中挑选看起来比较像真正的恐龙的图像,结果如下: 

比较以上图像,我们能发现使用聚类后产生的图像更可信,同时这些图像上的恐龙更像来自同一种类。使用全部图像得到的新恐龙形态差异较大,并且细节比较失真。
7、 图像识别
使用卷积神经网络(CNN)对得到的所有图像进行图像识别,结果为(欧洲,食肉性,兽脚亚目,侏罗纪)。能够看出地点和亚目属性与我们聚类的目标属性不同,亚目属性虽然有差异,但这两种亚目都在一个亚目组里,我们在聚类的时候正是对这一组进行聚类,因此结果是可信的。而地点属性可能是由于亚洲和欧洲经纬度比较接近所导致。
8、 预测新恐龙的其他属性
除了通过图像识别得到新恐龙的信息,我们还希望能够得到恐龙的体长、身高和体重。所以我们尝试对已有的属性进行分析,通过如线性回归和SVM回归对三个数据进行预测,但是结果非常不理想。我们试着将目标属性使用聚类分成几个小区间,再次使用分类进行预测,然而在训练集中的准确度也是非常不理想。因此我们放弃了这个想法。