
“白宫梦碎”——希拉里邮件分析
本文选自清华大学统计学研究中心开设的统计学辅修课程《数据科学导论》优秀学生成果
小组成员:
范昂之:清华大学数学科学系14级本科生
邵钰杉:清华大学软件学院 15级本科生
钟欣艺:清华大学外国语言文学系14级本科生
指导教师:俞 声

这份数据从邮件收发信息的角度来看,是半结构化的,但是邮件内容中的纯文本却是高度非结构化的,对于这样一组数据,我们决定从文本内容和收发关系入手研究。
1. 基于邮件内容的初步分析
观察一:希拉里生活起居大揭秘!
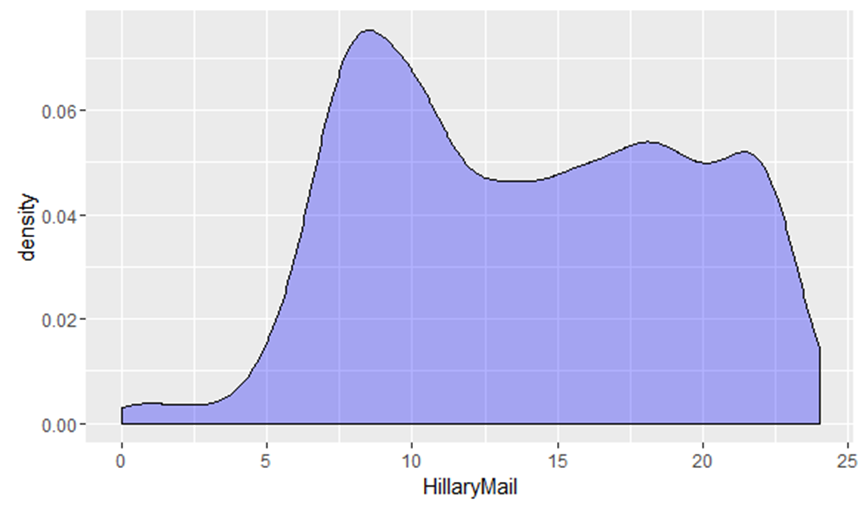 通过统计希拉里发邮件的时间,我们可以画出希拉里发邮件时间的密度函数,继而,我们可以推测出希拉里的生活习惯,例如起居时间等。从上图可以看到,希拉里起床的时间击败了绝大部分清华同学的起床时间,而入寝时间也相当晚。“这是一份一周7天,一天24小时的工作。你永远没有下班的概念。” 希拉里说。她本人也从美国媒体那里获得“劳模国务卿”的称号。而由我们数据中推测出的希拉里生活习惯也是希拉里努力工作的印证。
通过统计希拉里发邮件的时间,我们可以画出希拉里发邮件时间的密度函数,继而,我们可以推测出希拉里的生活习惯,例如起居时间等。从上图可以看到,希拉里起床的时间击败了绝大部分清华同学的起床时间,而入寝时间也相当晚。“这是一份一周7天,一天24小时的工作。你永远没有下班的概念。” 希拉里说。她本人也从美国媒体那里获得“劳模国务卿”的称号。而由我们数据中推测出的希拉里生活习惯也是希拉里努力工作的印证。
观察二:巴以和谈

观察“巴勒斯坦”和“以色列”这两个词的词频密度函数,我们发现它们有极大的相似性,并且在2010年9月达到高峰。查阅资料得知,中断近20个月的巴以直接和谈于2010年9月2日在美国首都华盛顿正式重启,此次和谈由希拉里主持。由于历史原因,巴以两国之间冲突不断,而美国一直扮演着在两国之间斡旋的重要角色。而两国对美国重要的战略意义使其在希拉里邮件之中维持着持久的话题热度。
观察三:希拉里时间线上的关键词
我们试图从整体上把握希拉里邮件内容的话题组成,于是我们建立了一个以邮件文本主题为资源的语料库。试图以词频分析来发现希拉里邮件的主要话题。我们在这里需要进行一些预操作。首先,我们要删除文本中的“停止词”,即stop words,这些大量的功能词对词频分析来说是一个大干扰。其次,基于英语语言的特殊性,我们对每个词汇进行了词根化处理,再经过其他一些处理之后,我们生成了这样的关键词云,词的大小与频率正相关。
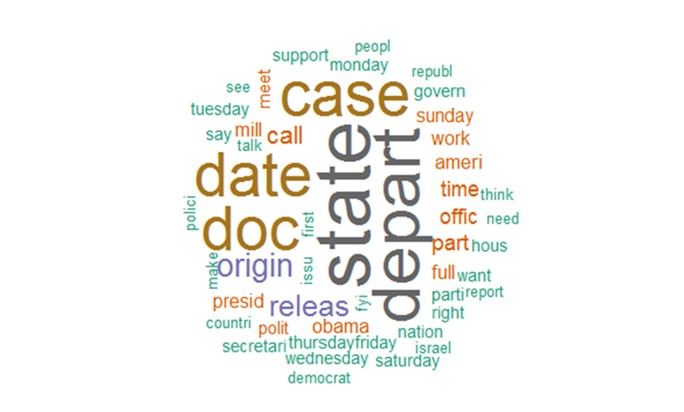 作为美国的国务卿,希拉里私人邮箱的话题,确实都集中在家国大事,这印证了之前所陈述的希拉里勤奋努力的断言,同时我们注意到右下角绿色字体的以色列,这是前50个高频词中出现的唯一一个除了美国之外的国家,由此可看出其之于美国的重要性。
作为美国的国务卿,希拉里私人邮箱的话题,确实都集中在家国大事,这印证了之前所陈述的希拉里勤奋努力的断言,同时我们注意到右下角绿色字体的以色列,这是前50个高频词中出现的唯一一个除了美国之外的国家,由此可看出其之于美国的重要性。
2. 基于收发关系的社交网络分析
我们试图仅从邮件的收发关系来分析希拉里服务器所涉及到的人物的社交模式。这个关系被一个385行*9730列的矩阵所刻画,矩阵中的元素a(i,j)所代表的是人物i在邮件j中的通信角色——发件人,收件人,抄送人。仅仅这一个矩阵,我们就可以做多方面的数据处理和分析工作。
(1)通信角色基本数据处理
首先按照发邮件的数量对这385个人进行了排序,
发送邮件前10名绘图如下:
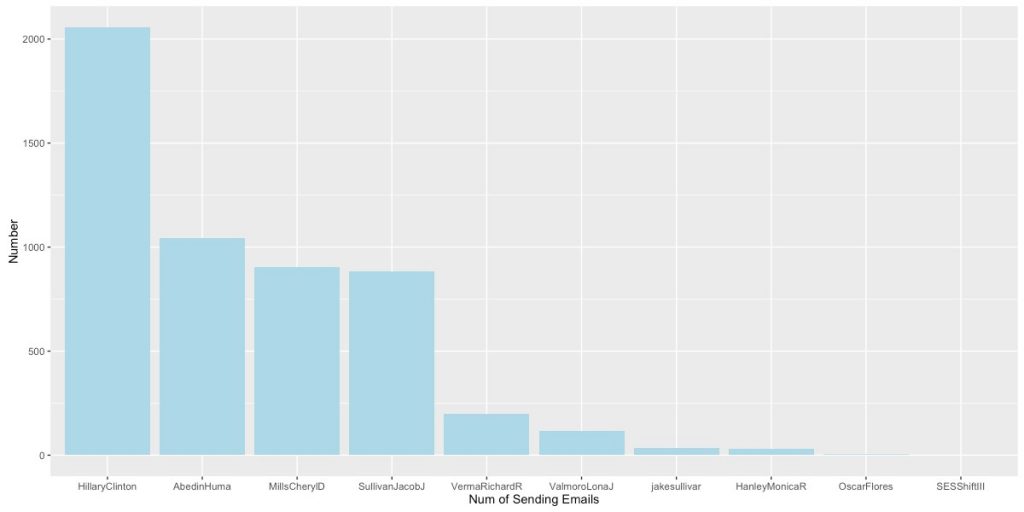
从图中我们可以看到,Clinton发送了超过2000封的邮件,发送邮件数量2、3、4名分别是Abedin Huma、Mills Chery和Sullivan Jacob。
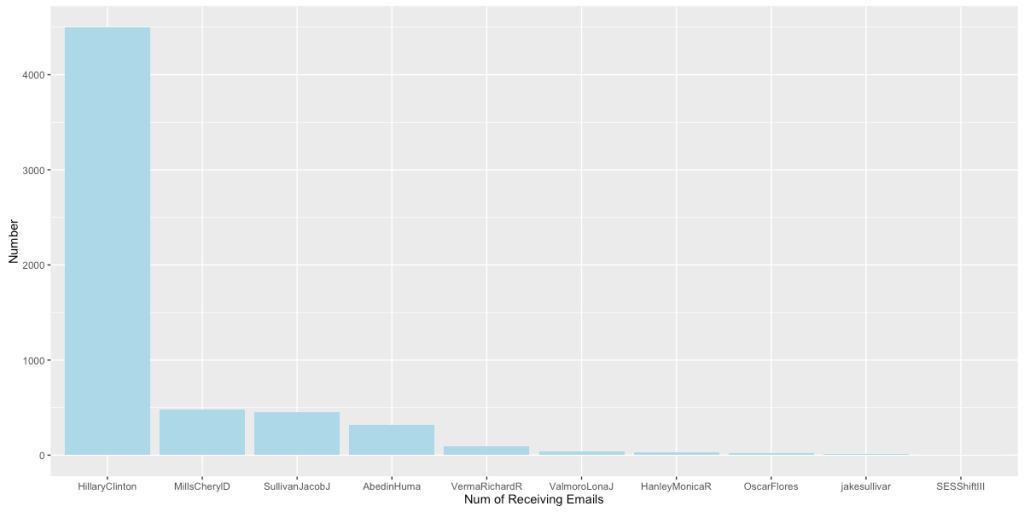
从图中我们可以看到,在这9730封邮件里Hillary收了4500封,排名2、3、4的Mills Chery、Sullivan Jacob和Huma收的邮件均不超过500封。不过考虑到这些邮件都是从希拉里的私人服务器中泄露出来的,这种现象也就不是很奇怪了。
被抄送邮件前10名绘图如下:
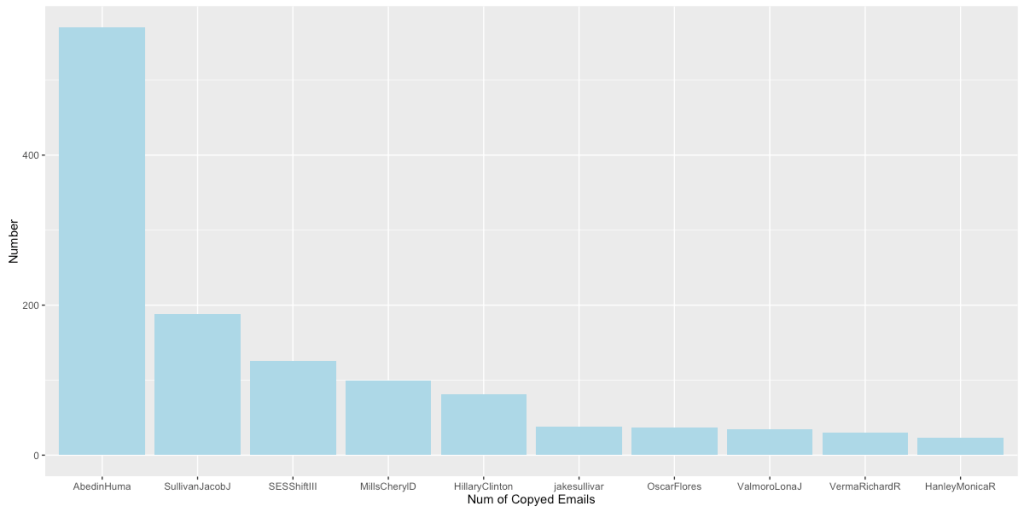
出人意料的是,被抄送邮件数量最多的不是Hillary,而是Huma。Hillary被抄送的邮件数量只排在第五位,甚至不如Mills Chery和Sullivan Jacob的数量多。由以上的分析和图表我们可以看出,Hillary是这个社交网络的核心,而在她周围也有一些在工作中关系很亲近的人,如Huma、Mills Chery和Sullivan Jacob。下面我们来以Hillary为核心对这个社交网络做一些分析。
社交网络分析
之前我们判断出了Hillary是这个社交网络的关键人物,现在我们首先来找到哪些人给Hillary发送的邮件数量最多。给Hillary发送邮件数量排名前十如下图:
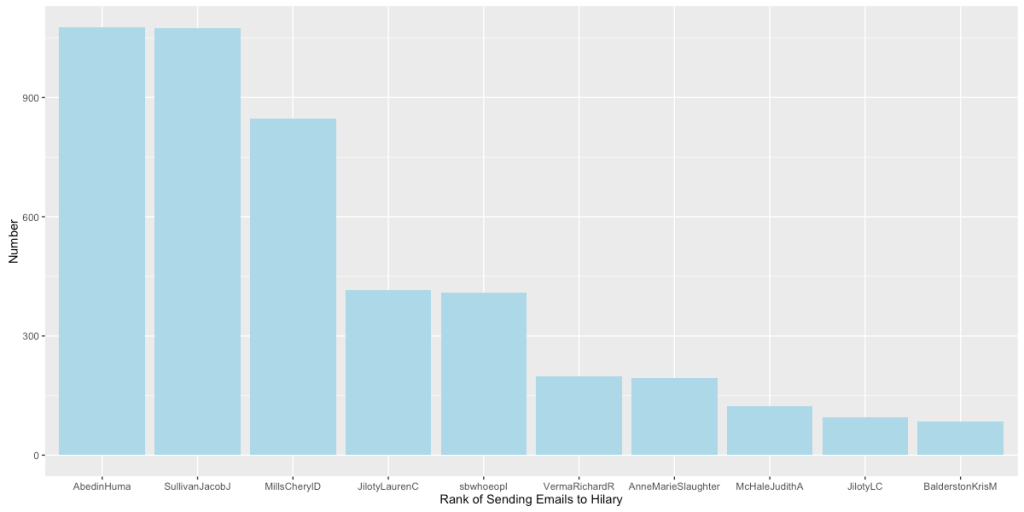
(2)希拉里邮箱相关联系人的社交模式探索
正如我们之前在前几个图中所看到的那样,Huma、Jacob和MillsChery是和希拉里关系最亲近的人。下面我们来更进一步地分析一下Hillary的社交网络,首先我们介绍一下所谓的『小世界原理』(Small World Experiment),这个现象主要描述了这样一个事实:世界上互不相识的人只需要不多的中间人就能建立起联系,著名的『六度分割理论』就是这个原理的具体应用。我们希望在Hillary的社交网络中也能观察到类似的现象。
为了获得更多的关于这个社交网络的信息,我们需要更细致的分析。首先我们把这个社交网络用图来建模,这样就可以运用图论的一些知识来探索这个社交网络,我们首先把这个社交网络建模成一个图G=(V,E) ,V 代表节点集,节点集中的元素是这385个人,E 代表边集合,如果两个人之间有过直接的邮件通信,就在这两人之间连一条边。基于这样的建模,通过一些代数运算就可以得到这个图G 的邻接矩阵inMatrix ,从而可以运用Warshall算法来观察这385个人和希拉里的联系情况。下面这张图展示了希拉里和这385个人之间的联系:

我们用度数(degree)来度量某一个人X和Hillary之间的距离,如果Hillary和X之间有直接的邮件联系,那么他们之间的degree是1;如果Hillary和X没有直接联系,但是Hillary与A有直接联系,A与X有直接联系,那么Hillary与X之间的degree是2……以此类推。这张图的横轴是度数(degree),纵轴是在给定度数下能够直接联系到Hillary的人。我们可以观察到一个奇怪的现象,在这385个人里面只有273人是可以直接或者间接联系到希拉里的,其他112个人和希拉里没有直接或间接的邮件联系,他们大多数人只有被抄送的邮件。这说明了这385个人组成的社交网络存在着严格的上下级关系,并不是一个扁平化管理的组织。
(3)寻找核心人物
正如我们在前面看到的那样,尽管在这个社交网络中有385人,大多数人和Hillary的关系不是那么紧密,我做的最后一项工作是找到Hillary的核心圈子。这里我用了Laplace谱二分法来寻找Hillary的核心圈子,首先我们得到这个图G 的Laplace矩阵,这个矩阵是一个非负定矩阵,从而我们可以找到这个矩阵倒数第二小的特征值和对应的特征向量,并依据这个特征向量来分类。这个算法的目的其实是把这个图G 分为两部分,使这两个部分之间连的边最少。最终我得到了Hillary的核心圈子如下所示:

我们可以看到其实希拉里的核心圈子只有36个人,而Huma、Mills Chery等人也赫然在列。这也印证了我们之前的结论。简而言之,这些邮件反映出这是一个以Hillary为中心人物,以Huma、Mills Chery等人为次核心人物,具有严格上下级关系的社交网络,Hillary位于这个网络中的一个包含36个人的核心圈子中。
3. 基于不同专业从事领域的人物分类及社区发现
(1)基本设计
无论从简单粗暴的邮件收发统计还是对图连通性破坏能力的分析,我们都可以得到希拉里身边重要人物的名单。依据之前的分析,我们发现希拉里邮件的社交网络是一个上下级关系明确的网络——希拉里与几个大人物紧密联系,大人物分管下属。据此我们初步打算希望得到一种基于收发邮件这个有向图来对人物进行小的社区分划,但结果并不尽如人意。后来,观察到希拉里身边的“大人物”各有专长,我们随即设想可以依据网络信息检索,判断整个社交网络中384个人每个人的专业领域,将之贴标签,以此进行社区分划。我们的社区分划思路是:首先建立分类的目标领域,其次搜索这些人的网络信息,找到可信的介绍文本后,依据文本内容将其归属到目标领域中的一个。最后,使用可视化方法直观呈现结论。根据对希拉里身边重要人物的分析,我们认为社交网络中的人主要集中在media, foreign policy, domestic policy and fund四个领域中。
(2) 网络数据抓取
接下来关键的,也是困难的一步,就是通过网络数据抓取技术获取各个人物的文本信息资料。由于我们手上的只有人物姓名,而且重名现象极为普遍,我们如何确定检索到的确实是目标人物?并且,如何确定检索到的信息具有强的可靠性,而不是奇怪的花边新闻?
解决方案:最后我们决定只认定维基百科作为可靠的信息来源,并且设计检索人物时加上“Hillary”这个关键词来确保搜到的人确实是在希拉里邮件圈里的目标人物,并且我们要求该人的维基页面必须在google搜索的前五个条目中以保证相关性。不得不承认我们的要求是非常苛刻的,但同时也非常准确。一些可能的改进方法是扩大可靠信息来源的认定范围。另一个缺失值补充的方法将在后文提到。
于是我们设计了这样一段python程序,他读入一个存有待检索姓名的csv文件作为key创建一个dictionary,然后在google中搜索人名,存储搜索到的前五个url链接地址,对其文本匹配,如果是维基的网址则存入dictionary作为该人的value,循环完整个dictionary的keys之后开始读取value中的url,保存目标网页的有效文本。
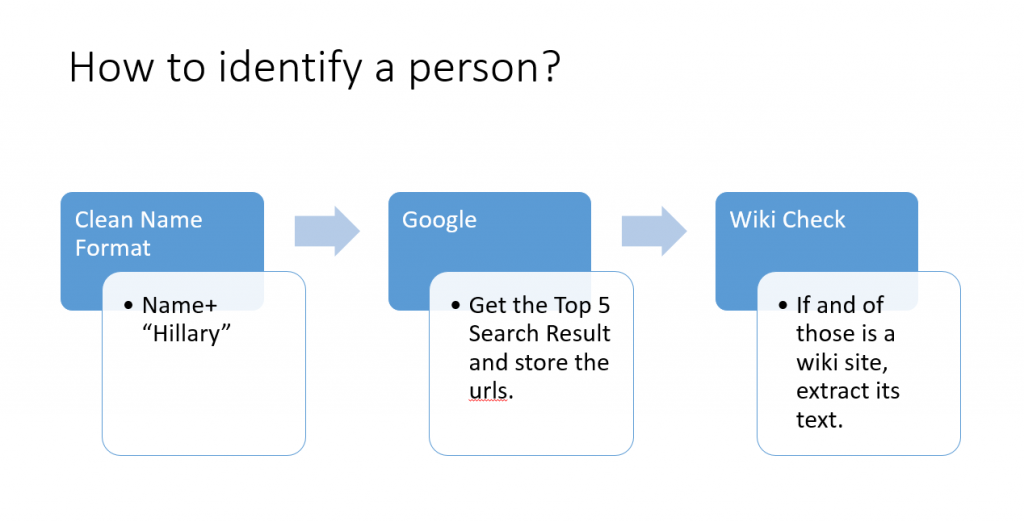
在克服了网络搜索方面的种种困难之后,我们最终成功收集到133个人的信息。注意到我们的筛选要求是极为严苛的,仍然有超过1/3的成功率,这说明希拉里私人邮件的传送对象较为知名。
(3)确定人物专长领域
我们随即建立了一个从人物信息文本到四个专长领域维度的映射函数。如下图。而我们选择分量最大的那一项作为人物专长领域的分类结果。
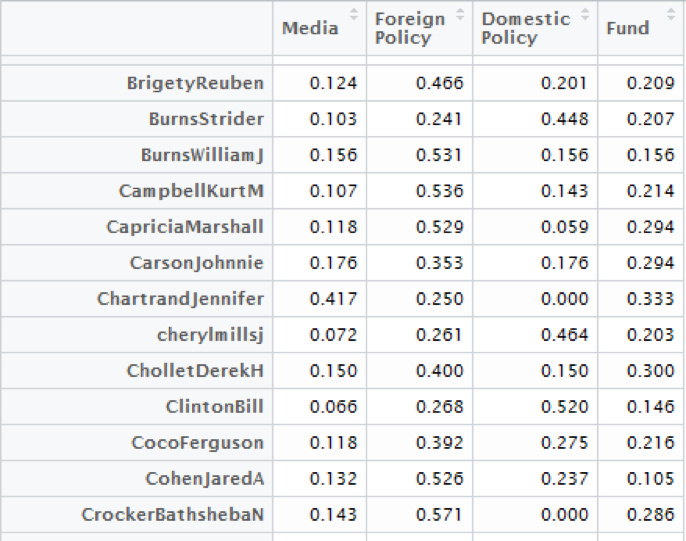
(4)社交模式与专长领域信息可视化呈现
联系以上所述之种种,如果能够用优秀的可视化手段来展现的话,可以更加直观清晰地体现数据带给我们的信息。我们可以建立这样一个图,图的节点是这个社交群体中的各个人物,而点点之间的距离则由两个人物之间信息交流密集程度来刻画,而点的颜色由我们探究所得人物专长领域来决定,那么,我们可以得到下图。如同之前所介绍的,呈现出明显的中心-边缘社交模式关系。

其中,媒体以蓝色标识,外交政策以粉橙色标识,国内政策以紫色标识,资金支持以绿色标识,未找到相关信息的暂且以灰色标识。
过滤掉重要程度不那么高的人并观察希拉里周围标注上人名的点,我们获得了信息更加明确的图。
 上图可以非常直观地看出,核心圈人物主要以国内外政策智囊为主。
上图可以非常直观地看出,核心圈人物主要以国内外政策智囊为主。 我们重点讨论一下在国内政策领域中和希拉里有强联系的Huma Abedin, 她在希拉里2016年的总统竞选中也扮演了重要的角色。她是希拉里竞选团队的副主席,同时也是希拉里从09-13年的得力助手。而她的丈夫,也在16年的总统竞选中扮演了极其重要的角色,被认为直接影响了大选的结果。
我们重点讨论一下在国内政策领域中和希拉里有强联系的Huma Abedin, 她在希拉里2016年的总统竞选中也扮演了重要的角色。她是希拉里竞选团队的副主席,同时也是希拉里从09-13年的得力助手。而她的丈夫,也在16年的总统竞选中扮演了极其重要的角色,被认为直接影响了大选的结果。
(5)分类有效性判定以及缺失值补充
注意到,在严苛的人物相关信息筛选标准下,有些人物的分类值是缺失的。对于这些人,我们也希望给他们贴标签。在本展示中,我们只对重要人物(36个)贴了标签。事实上我们的方法也可以应用到整个社交网络。我们的思路是通过“他人为自己投票”的方法来给他们贴标签。
假如一个人主要从事”Foreign Policy”,他与一封邮件A有关联(即至少为收件人、发件人、抄送者之一),并且邮件A与核心36人中的某些人有关联,那么就将这些人在”Foreign Policy”上的分数加上1。最终我们可以得到核心36人在4个领域的得分,即使他们没有维基百科。 如上图,通过“他人为自己投票”的方式,我们可以得知Sullivan Jacob J, Abedin Huma, Mills Cheryl D, Anne Marie Slaughter, Verma Richard R, Jiloty Lauren C各自分工的侧重。我们得到的结果与事实相符。
如上图,通过“他人为自己投票”的方式,我们可以得知Sullivan Jacob J, Abedin Huma, Mills Cheryl D, Anne Marie Slaughter, Verma Richard R, Jiloty Lauren C各自分工的侧重。我们得到的结果与事实相符。